图像
The Secrets of Salient Object Segmentation
- CVPR 2014.6
- 构建了 PASCAL-S 数据集,论证了该数据集的优越性
- 原图+完整分割图+注视数据+带排序的显著性分割真值图(通过多人点击实例实现)
- 利用已有显著物体分割算法、注视点预测算法:首先生成一组对象候选区域(CPMC算法),然后利用注视算法对不同区域的显著性进行排名(注视点的特征、决策树算法、逐像素预测显著性)
- 对显著性物体排序,在像素级别平均前K个分割来生成二元显著对象分割
- 严格来说不算SOR
Revisiting Salient Object Detection-Simultaneous Detection, Ranking, and Subitizing of Multiple Salient Objects
- CVPR 2018
- 使用PASCAL-S数据集
- 像素级方案
Relative Saliency and Ranking: Models, Metrics, Data and Benchmarks
- TMAPI 2019,与
作者相同 - 属于阶段B:提出了如何从segmentation、fixation创建用于SOR的真值数据的方法
- 使用了PASCAL-SR数据集;创建了COCO-SalRank数据集
- COCO-SalRank:结合SALICON的模拟眼动数据、MS COCO的实例级掩码数据,用一系列算法计算出每个实例的显著性排名
Inferring attention shift ranks of objects for image saliency
- CVPR 2020
- 使用注视转移顺序定义相对显著性
- 构建了一个大规模的显著对象排序数据集 ASR/ASSR,显示包含显著性排序顺序:
- 从MS COCO和SALICON构建,用三种方法,九种策略(4+1+4)
- 经过研究,选择 DistFixSeq 来生成真实的显著性排序
- 对象的显著性排序由观察者根据注意力转移顺序来定义。最终的显著性排序是多个观察者显著性排序的平均值
Salient object ranking with position-preserved attention
- ICCV 2021
- 第一个端到端的SOR任务框架,以多任务学习的方式解决该问题,可以共同优化 SOR 损失和检测损失(检测分支和显著物体排序分支是并行的,而不是顺序的)
- 使用ASSR数据集
Instance-level relative saliency ranking with graph reasoning
- TPAMI 2021
- 两阶段方案,首先分割显著实例,然后对其进行排名
- Mask R-CNN [15] 用于显著实例分割
- 显著性排名分支来排名每个分割实例的相对显著性
- 构建图推理模型,使用图神经网络(GNNs)推断相对显著性
- 提出了直接优化显著性排名顺序的改进的排名损失
- 创建了新的相对显著性排名数据集,具有大规模图像和人工注释的显著物体
- 提出了一种改进的SOR指标,涵盖检测、分割、排名三方面损失
Simultaneously Localize, Segment and Rank the Camouflaged Objects
- CVPR 2021
- 引入了伪装物体排序(COR)和伪装物体定位(COL)作为两个新任务,用于估计伪装物体的难度并识别使伪装物体显眼的区域
- 为上述两个任务提供了相应的训练和测试数据集,并贡献了最大的伪装物体检测测试数据集
- 首个基于排序的 COD 网络 (Rank-Net),提出了一个三重任务学习模型,可以同时对伪装物体进行定位、分割和排序
Bidirectional object-context prioritization learning for saliency ranking
- CVPR 2022
- 一种新的双向方法,将空间注意力与基于物体的注意力统一用于显著性排名
- 提出了一个新颖的选择性物体显著性(SOS)模块用于建模基于物体的注意力
- 提出了一个新颖的物体-上下文-物体关系(OCOR)模块,通过推理物体在双向物体-上下文和上下文-物体中的关系来建模空间注意力
Partitioned Saliency Ranking with Dense Pyramid Transformers
- ACMMM 2023
- 一般来说,个人同时选择 $N$ 个最显著的实例要比准确确定显著实例的顺序简单得多。
- 将无序的显著实例分割成多个分区,然后根据这些分区之间的相关性进行排名
- 在ASSR和IRSR数据集上实验
Rethinking Object Saliency Ranking: A Novel Whole-Flow Processing Paradigm
- TIP 2023
- 本文对问题产生的原因进行了深入分析,并从“GT数据生成”、“网络结构设计”和“训练流程”三个方面提出了显著性排名任务的全流程处理范式
- SOR领域现有的问题——解决方案
- 显著性排名真实值(GT)生成方法不够合理
- 提出新颖的关系感知显著性排名GT顺序生成方法(RA-SRGT),可以直接从注视点中推导出来,无需重新标注
- 利用不同水平的显著性阈值生成与人类视觉系统(HVS)基本原理密切对齐的显著性排名GT顺序
- 训练排名模型依然具有挑战性,因为大多数显著性排名方法采用多任务范式,导致不同任务之间存在冲突和权衡
- 利用已经高性能且经过预训练的目标检测模型离线获取对象提议,避免多任务学习
- 简单而高效的基于提议的单任务框架,称为灵活对象显著性排名网络(FOSRNet)
- 现有基于回归的显著性排名方法对于显著性排名模型来说过于复杂,需要大量数据才能准确执行
- 使用纯物体级别分类来预测显著性排名顺序,而非逐像素预测
- 显著性排名真实值(GT)生成方法不够合理
- 利用RA-SRGT标注SALICON数据集
RGB-D salient object ranking based on depth stack and truth stack for complex indoor scenes
- PR 2023
- 构建了一个包含多个对象的复杂室内场景的RGB-D显著性对象排名数据集
- 不仅包含实例被标记为显著对象的次数,还包括标注者注意到对象的顺序
- 显著性排名基于观察者注意到这些对象的顺序定义,最终的排名结果是13位观察者的显著性排名的平均值
- 提出了一个端到端的学习网络,以基于深度堆叠和真实标签堆叠对显著性对象进行排序
HyperSOR: Context-Aware Graph Hypernetwork for Salient Object Ranking
- TPAMI 2024
- 建立了一个包含 24,373 张图像的大规模 SOR 数据集,其中包含丰富的上下文注释,即场景图、分割标注和显著性排序
- 提出了一种新型的图超网络,名为 HyperSOR,用于考虑上下文的 SOR
- 首先开发了一个初始图模块,用于检测对象并通过语义信息构建初始图
- 提出了一个基于多级图神经网络的场景感知模块,该模块能够捕捉场景上下文并生成场景图
- 设计了一个基于超网络的排序预测模块,动态嵌入所学习的场景上下文,从而能够准确推断对象的显著性排序
Advancing Saliency Ranking with Human Fixations: Dataset, Models and Benchmarks
- CVPR 2024
- 介绍了第一个大规模的SRD数据集SIFR,该数据集使用真实的人类注视数据构建(而非鼠标轨迹)
- 使用从 MS-COCO 中挑选的图像,专注于包含至少三个物体的场景,计算了多个用户在每个场景中的眼动注视时间
- 对给定场景中可能的显著实例数量不设上限
- 提出了QAGNet,这是一种新颖的模型,利用来自transformer检测器的显著性实例查询特征,在三层嵌套图中进行处理
- 不限制输出数量,包括了低显著性物体
Domain Separation Graph Neural Networks for Saliency Object Ranking
- CVPR 2024
- 提出了一种新颖的域分离图神经网络(DSGNN)
- 首先分别从每个对象中提取形状和纹理线索,并为所有对象构建形状图和纹理图
- 然后,我们提出了形状-纹理图域分离(STGDS)模块,通过分别明确建模每对对象之间的形状和纹理关系,来分离目标对象的任务相关和无关信息
- 此外,我们引入了跨图像图域分离(CIGDS)模块,旨在探索对不同场景具有鲁棒性的显著性程度子空间,从而为在不同图像中具有相同显著性水平的目标创建统一的表示
- 我们的 DSGNN 自动学习多维特征来表示每个图边,允许复杂、多样且与排序相关的关系进行建模
视频
Ranking Video Salient Object Detection
- ACMMM 2019
- 构建了一个排序视频显著目标数据集(RVSOD)
- 计算每一帧中落在每个目标上的眼动追踪点的数量比例,来衡量目标之间的相对显著性排序
- 构建了一个名为合成视频显著性网络(SVSNet)的新型神经网络,用于检测视频中的传统显著目标和人眼运动
- 排序显著性模块(RSM)将SVSNet的结果作为输入,以生成显著性排序图
Rethinking Video Salient Object Ranking
- arxiv 2022
- 显式学习不同显著目标之间的空间和时间关系,以生成显著性排名
- 提出了一个涵盖不同视频类型和多样化场景的大规模新数据集
- 提出了一种用于视频显著目标排序(VSOR)的端到端方法
- 一个帧内自适应关系(IAR)模块,用于在同一帧中局部和全局地学习显著目标之间的空间关系
- 一个帧间动态关系(IDR)模块,用于建模跨帧的显著性时间关系
全景图 —— 显著性
包含 MC2 所有全景图相关论文,不一定与SOR有关
Look around you: Saliency maps for omnidirectional images in VR applications
- QoMEx 2017
- !!
A Dataset of Head and Eye Movements for 360 Degree Images
- MMSys’17 2017
- !!
A simple method to obtain visual attention data in head mounted virtual reality
- ICMEW 2017
- !!
Head movements during visual exploration of natural images in virtual reality
- CISS 2017
- !!
A subjective visual quality assessment method of panoramic videos
- ICME 2017 MC2
- 背景
- 全景视频包含在头戴式显示设备支持下的球面观看方向,从而提升了沉浸式和交互式的视觉体验
- 目前很少有针对全景视频的主观视觉质量评估(VQA)方法
- 建立了一个包含多个受试者观看全景视频时的观看方向数据的数据库(VR-VQA48)
- 发现不同受试者在全景视频上的观看方向存在高度一致性
- 提出了一种针对受损全景视频质量损失的主观VQA方法
- 提出了一种由不同受试者进行的主观测试程序,用以测量全景视频的质量,得出不同的平均意见得分(DMOS)
- 为了配合全景视频观看方向的不一致性,我们进一步提出了一种向量化DMOS指标
- 实验结果验证了我们的主观VQA方法,无论是以整体还是向量化DMOS指标的形式,都能有效测量全景视频的主观质量
Scanpath and saliency prediction on 360 degree images
- 2018
The prediction of head and eye movement for 360 degree images
- 2018
Saliency in VR: How Do People Explore Virtual Environments?
- TVCG 2018
- !!
Bridge the Gap Between VQA and Human Behavior on Omnidirectional Video: A Large-Scale Dataset and a Deep Learning Model
- ACMMM 2018 MC2
- 背景
- 全景视频提供了360×180°的观看范围的球面刺激
- 观察者只能通过头部运动(HM)看到全景视频的视口区域
- 而在视口内,只有更小的区域可以通过眼动(EM)清晰感知
- 因此,全景视频的主观质量可能与人类行为的HM和EM相关
- 出了一个大规模的全景视频视觉质量评估(VQA)数据集,称为VQA-ODV
- 收集了60个参考序列和540个受损序列
- 不仅提供了序列的主观质量得分,还提供了受试者的HM和EM数据
- 发现全景视频的主观质量确实与HM和EM有关
- 开发了一个深度学习模型
- 模型嵌入了HM和EM,用于全景视频的客观VQA
- 实验结果表明,我们的模型显著提高了全景视频VQA的最新技术水平
GBVS360, BMS360, ProSal: Extending existing saliency prediction models from 2D to omnidirectional images
- 2018
360-aware Saliency Estimation with Conventional Image Saliency Predictors
- 2018
A novel superpixel-based saliency detection model for 360-degree images
- 2018
Salnet360: Saliency maps for omni-directional images with cnn
- 2018
Saliency map estimation for omnidirectional image considering prior distributions
- 2018
A saliency prediction model on 360 degree images using color dictionary based sparse representation
- 2018
Predicting Head Movement in Panoramic Video: A Deep Reinforcement Learning Approach
- TPAMI 2019 MC2
- 背景
- 全景视频通过允许人类通过头部运动(HM)控制视野(FoV),提供了沉浸式和交互式的体验
- HM在全景视频的人类注意力建模中起着关键作用
- 本文建立了一个数据库(PVS-HM),收集了受试者在全景视频序列中的HM数据
- 发现不同受试者的HM数据高度一致
- 发现深度强化学习(DRL)可以应用于预测HM位置,通过最大化模仿人类HM扫描路径的奖励来实现
- 提出了一个基于DRL的HM预测(DHP)方法,包括离线-DHP和在线-DHP
- 离线-DHP
- 运行多个DRL工作流程以确定每个全景帧的潜在HM位置
- 然后,生成潜在HM位置的热图,称为HM图,作为离线-DHP的输出
- 在线-DHP
- 根据当前观察到的HM位置估计一个受试者的下一个HM位置
- 这是通过在学到的离线-DHP模型上开发DRL算法来实现的
- 离线-DHP
- 实验验证了:
- 我们的方法在全景视频的HM位置的离线和在线预测中都是有效的
- 学到的离线-DHP模型可以提高在线-DHP的性能
Assessing Visual Quality of Omnidirectional Videos
- TCSVT 2019 MC2
- 是《A subjective visual quality assessment method of panoramic videos》的发展
- 背景
- 全景视频支持球面观看方向,并可配合头戴式显示器使用,提供了一种交互式和身临其境的体验
- 目前很少有针对全景视频编码的视觉质量评估(VQA)方法,无论是主观的还是客观的
- 本文提出了评估全景视频编码质量损失的主观和客观方法
- 首先介绍了一个新的(?)数据库(VR-HM48/VR-VQA48),其中包含了多个受试者观看全景视频序列时的观看方向数据
- 发现不同受试者的观看方向具有高度的一致性。观看方向通常在前区域中心呈正态分布,但有时也会落入其他与视频内容相关的区域
- 提出了一种主观VQA方法,用于测量整体和区域全景视频的差异平均意见得分(DMOS)
- 整体DMOS(O-DMOS)
- 向量化DMOS(V-DMOS)
- 提出了两种客观VQA方法,这些方法考虑了全景视频的人类感知特性
- 根据像素与前区域中心的距离对像素失真进行加权,这考虑了人类在全景图中的偏好
- 根据视频内容预测观看方向,然后利用预测的观看方向在我们的客观VQA方法中为每个像素的失真分配权重
- 首先介绍了一个新的(?)数据库(VR-HM48/VR-VQA48),其中包含了多个受试者观看全景视频序列时的观看方向数据
- 实验结果验证了本文提出的主观和客观方法都推进了全景视频VQA的最新技术。
Viewport Proposal CNN for 360° Video Quality Assessment
- CVPR 2019
- 背景
- 近年来,人们对360°视频的视觉质量评估(VQA)的兴趣日益浓厚
- 现有的VQA方法并没有考虑到以下事实
- 观察者只看到360°视频的视口,而不是图像块或整个360°帧
- 在视口内,只有显著的区域才能被观察者以高分辨率感知
- 本文提出了一种基于视口的卷积神经网络(V-CNN)方法,用于360°视频的VQA
- 同时考虑了视口提议和视口显著性预测这两个辅助任务
- V-CNN方法由两个阶段组成,即视口提议和VQA
- 第一阶段,开发了视口提议网络(VP-net),作为第一辅助任务,用以产生几个潜在的视口
- 第二阶段,设计了一个视口质量网络(VQ-net),用于为每个提议的视口评定VQA得分
- 在这一过程中预测视口的显著性图,然后将其用于VQA得分评定,完成另一个辅助任务——视口显著性预测
- 通过整合所有视口的VQA得分,可以完成360°视频VQA的主要任务
- 实验(VAQ-ODV数据集)验证了我们的V-CNN方法在显著提升360°视频VQA的最新技术水平方面的有效性
- 我们的方法在两个辅助任务中也取得了相当的表现
State-of-the-Art in 360° Video/Image Processing: Perception, Assessment and Compression
- JSTSP 2020 MC2
- 背景
- 360°视频/图像越来越受欢迎并引起了广泛关注
- 由于360°视频/图像的球面视角范围涉及大量数据,这对解决存储、传输等瓶颈的360°视频/图像处理提出了挑战
- 因此,近年来涌现出了大量关于360°视频/图像处理的研究工作
- 本文从感知、评估和压缩三个方面回顾了360°视频/图像处理的最新研究进展
- 首先,本文回顾了360°视频/图像的相关数据集和视觉注意力建模方法
- 其次,我们综述了360°视频/图像在主观和客观视觉质量评估(VQA)方面的相关研究
- 第三,我们概述了360°视频/图像的压缩方法,这些方法或是利用了球面特性,或是结合了视觉注意力模型
- 最后,我们总结了本文的综述内容,并展望了360°视频/图像处理领域的未来研究趋势
Viewport-Dependent Saliency Prediction in 360° Video
- TM 2020 MC2
- 背景
- 传统图像和视频中的显著性预测近年来引起了广泛的研究兴趣
- 针对360°视频的显著性预测研究较少,现有工作主要集中在直接预测整个全景图中的注视点
- 当观看360°视频时,人们只能观察到视口中的内容,这意味着在任何给定时刻只能看到360°场景的一部分
- 研究了360°视频视口中的人类注意力,并提出了一种新颖的视觉显著性模型,称为视口显著性(viewport saliency),用于预测360°视频中的注视点
- 首先,我们发现人们的注视位置受360°视频视口内容和位置的影响
- 我们在两个最近的基准数据库中(《Predicting Head Movement in Panoramic Video: A Deep Reinforcement Learning Approach》《Gaze Prediction in Dynamic 360° Immersive Videos》),对200多个360°视频和30多名受试者进行了研究
- 其次,我们提出了一种多任务深度神经网络(MT-DNN)方法,用于360°视频中的视口显著性(VS)预测
- 该方法考虑了视口的输入内容和位置
- 首先,我们发现人们的注视位置受360°视频视口内容和位置的影响
- 大量实验和分析表明,我们的方法在该任务上优于其他最先进的方法
Viewport-Based CNN: A Multi-Task Approach for Assessing 360° Video Quality
- TPAMI 2020 MC2
- related, but video
- 总结了 360视频 的 数据集、VQA、显著性模型、基于显著性模型的VQA
- 背景
- 对于360°视频,现有的视觉质量评估(VQA)方法主要基于整个帧或裁剪的区域,忽略了观众只能访问视口的事实
- 提出了一种针对360°视频的视口基础的VQA两阶段多任务方法
- 建立了一个大规模的360°视频VQA数据集,称为VQA-ODV
- 通过挖掘我们的数据集,我们发现360°视频的主观质量与摄像机运动、视口位置以及视口内的显著性有关
- 提出了一种视口基础的卷积神经网络(V-CNN)方法用于360°视频的VQA
- 该方法具有一个新颖的多任务架构,由视口提案网络(VP-net)和视口质量网络(VQ-net)组成
- VP-net处理摄像机运动检测和视口提案等辅助任务
- VQ-net则完成视口显著性预测的辅助任务和VQA的主要任务
- 建立了一个大规模的360°视频VQA数据集,称为VQA-ODV
- 实验验证了我们的V-CNN方法在360°视频VQA上的性能显著提升,并且在三个辅助任务中也表现出色
Attention-Based Deep Reinforcement Learning for Virtual Cinematography of $360^{\circ}$ Videos
- TM 2020 MC2
- related, but video
- 背景
- 虚拟电影摄影指的是从整个360°视频中自动选择看起来自然的正常视场(NFOV)
- 虚拟电影摄影可以被建模为一个深度强化学习(DRL)问题,其中 agent 根据360°视频帧的环境执行与NFOV选择相关的操作
- 所选择的NFOV明显比其他区域更吸引注意,即NFOV具有较高的显著性
- 提出了一种基于注意力的DRL(A-DRL)方法用于360°视频的虚拟电影摄影
- 开发了一个新的DRL框架,用于自动NFOV选择,其输入包括每个360°帧的内容和显著性图
- 为我们的方法中的DRL框架提出了一个新的奖励函数,该函数考虑了显著性值、真实值和NFOV选择的平滑过渡随后,设计了一个简化的DenseNet(称为Mini-DenseNet)来通过最大化奖励来学习最优策略
- 大量实验表明,我们的A-DRL方法在Sports-360视频和Pano2Vid数据集上优于其他最先进的虚拟电影摄影方法
LAU-Net: Latitude Adaptive Upscaling Network for Omnidirectional Image Super-Resolution
- CVPR 2021 MC2
- not so related
- 背景
- 传统的二维(2D)图像超分辨率方法对球形 ODI 效果不佳,因为 ODI 的像素密度分布不均且不同纬度的纹理复杂度各异
- 提出了一种新颖的纬度自适应上采样网络(LAU-Net)用于 ODI 超分辨率,该方法允许不同纬度的像素采用不同的上采样因子
- 引入了拉普拉斯多级分离结构,将 ODI 划分为不同的纬度带,并用不同的因子进行分层上采样
- 提出了一种具有纬度自适应奖励的深度强化学习方案,以自动选择不同纬度带的最佳上采样因子
- 首次考虑纬度差异用于 ODI 超分辨率的尝试,实验结果表明,我们的 LAU-Net 显著提高了 ODI 的超分辨率性能
Saliency Prediction on Omnidirectional Image With Generative Adversarial Imitation Learning
- TIP 2021 MC2
- very related
- 背景
- 在观看全景图像(ODI)时,受试者可以通过移动头部来访问不同的视口。
- 因此,预测受试者在ODI上的头部注视点(head fixation)是必要的
- 建立了一个用于全景图像注视的数据集(AOI)
- 规模较大,包含了30名受试者观看600张ODI的头部注视数据
- 头部注视点在受试者之间具有一致性,并且随着受试者数量的增加,这种一致性也增加
- 头部注视点存在前中心偏差(FCB)
- 受试者之间的头部运动幅度类似
- 提出了一种新颖的方法来预测ODI上的头部注视点显著性,称为SalGAIL
- 应用深度强化学习(DRL)来预测一个受试者的头部注视点
- GAIL学习DRL的奖励,而不是传统的人工设计奖励
- 开发了多流DRL来生成不同受试者的头部注视点,并通过卷积预测的头部注视点生成ODI的显著性图
- 验证了我们的方法在预测ODI显著性图方面的有效性,显著优于11种最先进的方法
Spatial Attention-Based Non-Reference Perceptual Quality Prediction Network for Omnidirectional Images
- ICME 2021 MC2
- related
- 背景
- 由于视觉注意力与感知质量之间的强相关性,许多方法尝试利用人类显著性信息来进行图像质量评估
- 尽管这种机制能够获得良好的性能,但这些网络需要人类显著性标签,而这在全景图像(ODI)中并不容易获得
- 提出了一种基于空间注意力的感知质量预测网络,用于全景图像的无参考质量评估(SAP-net)
- 建立了一个大规模的全景图像图像质量评估数据集(IQA-ODI),该数据集包含了200名受试者对1080张全景图像的主观评分
- 120张高质量的全景图像作为参考,另外960张全景图像存在JPEG压缩和地图投影的损伤
- 在没有任何人类显著性标签的情况下,通过自注意力机制自适应地估计损伤全景图像的感知质量,显著提升了质量评分的预测性能
Hierarchical Bayesian LSTM for Head Trajectory Prediction on Omnidirectional Images
- TPAMI 2022 MC2
- related
- 建立了一个大型数据集(HTRO),收集了1080个ODIs上的21600条头部轨迹
- 发现了两个影响头部轨迹的重要因素,即时间依赖性和个体特异性差异
- 提出了一种将分层贝叶斯推理 (HBI) 整合到长短期记忆网络 (LSTM) 中的新方法,用于ODIs上的头部轨迹预测,称为HiBayes-LSTM
- 开发了一种未来意图估计 (FIE) 机制,用于捕捉先前、当前和预估的未来信息中的时间相关性,以预测视口转换
- 开发了一种称为分层贝叶斯推理 (HBI) 的训练方案,用于在HiBayes-LSTM中建模个体间的不确定性
- 对于HBI,我们在层级中引入了联合高斯分布,以近似网络权重的后验分布
- 在ODIs轨迹预测上显著优于9种最先进的方法,并且成功应用于ODIs的显著性预测
- 头部轨迹 -> 头部固视点 -> 高斯核卷积 -> 显著性图,需要融合多条头部轨迹的结果
Omnidirectional Image Super-Resolution via Latitude Adaptive Network
- TM 2022 MC2
- not so related
- 背景
- 低分辨率的全向图像恢复高分辨率的全向图像,即全向图像超分辨率(ODI-SR),是非常必要的
- 提出了一种新颖的纬度感知上采样网络,称为LAU-Net+,不同的纬度带可以学习采用不同的上采样因子
- 引入了一个拉普拉斯多级金字塔网络,其中随着级别数量的增加,上采样因子逐渐增加
- 每个级别由一个特征增强模块(FEM)、一个带选择决策模块(DDM)和一个高纬度增强模块(HEM)组成
- FEM模块用于增强从输入ODI中提取的高层次特征
- DDM的作用是动态地丢弃不必要的高纬度带,并将剩余的带传递到下一级
- 开发了一种带有纬度自适应奖励的强化学习方案
- HEM模块用于进一步增强丢弃纬度带的高层次特征,采用了轻量级的架构
- 首个将纬度特性考虑用于ODI-SR任务的工作,实验结果表明,我们的LAU-Net+在各种ODI数据集上,在ODI-SR任务中,定量和定性表现都达到了最新的研究水平
TVFormer: Trajectory-guided Visual Quality Assessment on 360° Images with Transformers
- ACMMM 2022 MC2
- related
- 背景
- 现有的360°图像BVQA方法忽略了视口交互中头部轨迹的动态特性,因此未能获得类似人类的质量评分
- 提出了一种新颖的基于Transformer的轨迹引导360°图像质量评估方法(称为TVFormer),能够同时完成360°图像的头部轨迹预测和BVQA任务(使用 ODI-IQA 数据集)
- 第一个任务中,我们开发了一个轨迹感知记忆更新器(TMU)模块,用于保持预测头部轨迹的一致性和准确性
- 为了捕捉时间顺序视口之间的长距离质量依赖性,我们在TVFormer的编码器中为BVQA任务提出了一个时空分解自注意力(STF)模块
- TVFormer在三个基准数据集上相比于最先进的方法具有优越的BVQA性能
Blind VQA on 360° Video via Progressively Learning From Pixels, Frames, and Video
- TIP 2022 MC2
- not so related
- 背景知识
- 需要对360°视频进行视觉质量评估(VQA),以衡量压缩引起的质量退化,并进一步指导VR系统的优化以提高QoE
- 考虑了人类对球面视频质量的渐进感知模式,并提出了一种新的360°视频盲质量评估方法(即ProVQA),通过从像素、帧和视频中逐步学习来实现
- 设计了三个子网,即球面感知质量预测子网(SPAQ)、运动感知质量预测子网(MPAQ)和多帧时间非局部子网(MFTN)
- SPAQ子网首先基于人类的球面感知机制对空间质量退化进行建模
- MPAQ子网通过利用相邻帧之间的运动线索,适当地结合了运动上下文信息,用于360°视频的质量评估
- MFTN子网通过探索多帧的长期质量关联,聚合多帧的质量退化,得出最终的质量评分
DINN360: Deformable Invertible Neural Network for Latitude-Aware 360deg Image Rescaling
- CVPR 2023 MC2
- not so related
- 提出了首个针对360°图像的缩放方法,即将360°图像缩小为视觉上有效的低分辨率(LR)图像,然后根据该低分辨率图像放大为高分辨率(HR)360°图像
- 首先分析了两个360°图像数据集,并观察到了一些关于360°图像在纬度方向上如何变化的特点
- 提出了一种新颖的可变形可逆神经网络(INN),称为DINN360,用于感知纬度的360°图像缩放
- 设计了一个可变形的INN来缩小LR图像,并通过自适应处理不同纬度区域发生的各种变形,将高频(HF)分量投射到潜在空间
- 给定缩小后的LR图像,通过从潜在空间恢复与结构相关的HF分量,以条件纬度感知的方式重建高质量的HR图像
- 在四个公共数据集上进行的大量实验表明,我们的DINN360方法在2×、4×和8×的360°图像缩放任务中,显著优于其他最先进的方法
全景图 —— 分割
Object detection in equirectangular panorama
- ICPR 2018
WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving
- ICCV 2019
- 目标为自动驾驶,且是鱼眼镜头,不合适
Semantic segmentation of panoramic images using a synthetic dataset
- AIMLDA 2019
- 背景
- 全景图像因其大视场(FoV)在信息容量和场景稳定性方面具有优势
- 提出了一种合成全景图像数据集的方法
- 设法将从不同方向拍摄的图像拼接成全景图像,连同它们的标注图像
- 生成了被称为 SYNTHIA-PANO 的全景语义分割数据集
- 实验结果表明,使用全景图像作为训练数据对分割结果是有益的
- 使用具有180度视场的全景图像作为训练数据,模型具有更好的性能
- 用全景图像训练的模型还具有更好的抵抗图像畸变的能力
Orientation-Aware Semantic Segmentation on Icosahedron Spheres
- ICCV 2019
- 背景
- 在球面领域(spherical domain),最近有几种方法采用了二十面体网格
- 但这些系统通常是旋转不变的,或者需要大量的内存和参数,因此只能在非常低的分辨率下执行
- 我们为二十面体网格提出了一个方向感知的CNN框架
- 我们的设计简化为经典CNN的标准网络操作,但在考虑球面上特征的北向对齐核卷积
- 展示了其在达到8级分辨率网格(相当于640×1024的等矩形图像)的内存效率
- 由于我们的核在球体的切线方向上操作,因此可以在只有很小的权重调整需求的情况下,直接转移在透视数据上预训练的标准特征权重
- 我们的方向感知CNN成为了最近2D3DS数据集的新最佳状态,并且我们的Omni-SYNTHIA版本的SYNTHIA也达到了这一水平

PASS: Panoramic annular semantic segmentation
- ITS 2019
- 背景
- 像素级语义分割能够统一大多数驾驶场景感知任务
- 前主流的语义分割器主要针对具有狭窄视场(FoV)的数据集进行基准测试,而且大部分基于视觉的智能车辆仅使用面向前方的摄像头
- 提出了一种全景环状语义分割(PASS)框架,基于紧凑的全景环状镜头系统和在线全景展开过程(online panorama unfolding process)来感知整个周围环境
- 为了便于PASS模型的训练,我们利用传统的FoV成像数据集,避免了创建完全密集的全景注释所需的努力
- 为了在展开的全景中持续利用丰富的上下文线索,我们调整了我们的实时ERF-PSPNet,以在不同部分预测语义有意义的特征图,并将其融合以完成全景场景解析
- 创新之处在于网络适应性,以实现平滑无缝的分割,结合扩展的异构数据增强集以获得在全景图像中的鲁棒性
- 实验证明了PASS在单一PASS中对现实世界周围感知的有效性

Large scale joint semantic re-localisation and scene understanding via globally unique instance coordinate regression
- BMVC 2019
DS-PASS: Detail-sensitive panoramic annular semantic segmentation through SwaftNet for surrounding sensing
- IVS 2020
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 语义解释交通场景对于自动驾驶运输和机器人系统至关重要
- 现有的最先进的语义分割流程主要是为针孔相机设计,并使用视野狭窄(FoV)的图像进行训练
- 提出了一个网络适应框架,实现全景环状语义分割(PASS),允许重新使用传统的针孔视图图像数据集
- 在细节关键的编码器层和上下文关键的解码器层之间实现基于注意力的横向连接,适应了我们提出的SwaftNet,以增强对细节的敏感性
- 在全景分割上使用扩展的PASS数据集对高效分割器的性能进行了基准测试,证明了所提出的实时SwaftNet超过了现有的高效网络
- 评估了在移动机器人和仪器车辆上部署细节敏感的PASS(DS-PASS)系统的实际性能
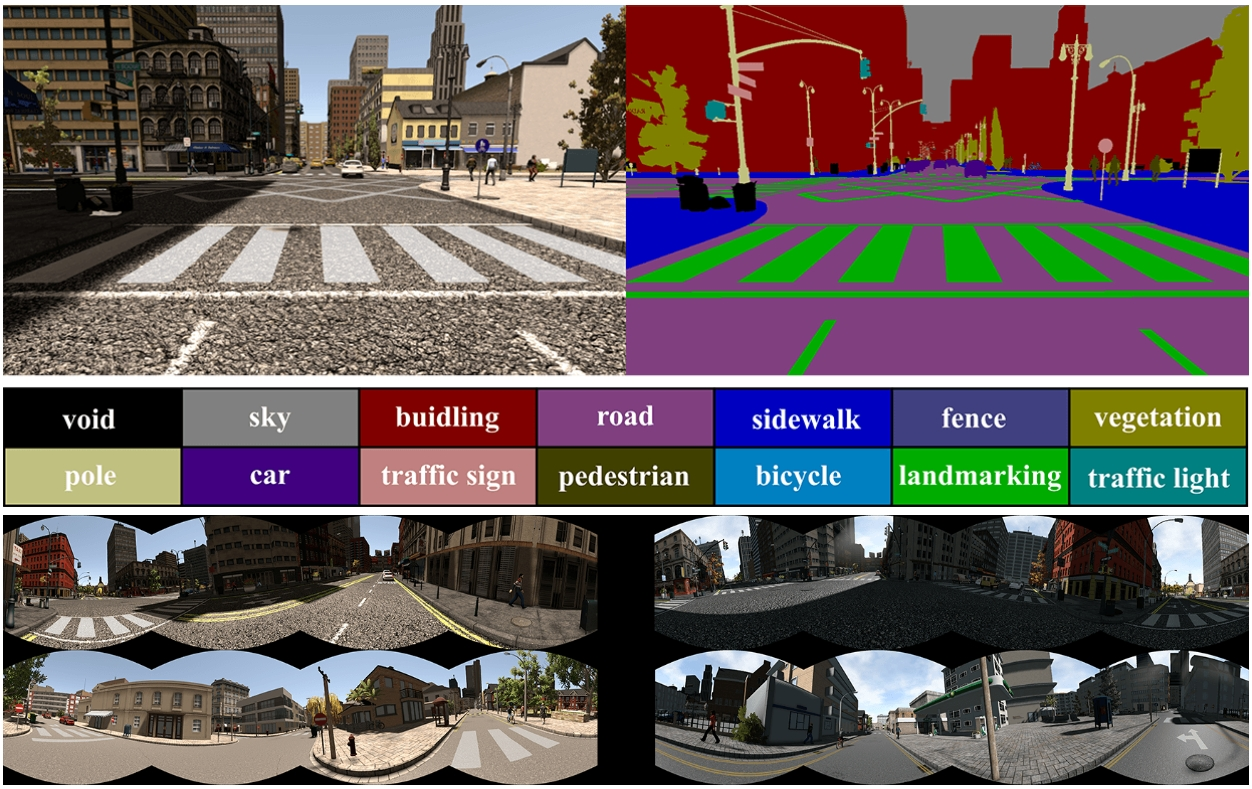
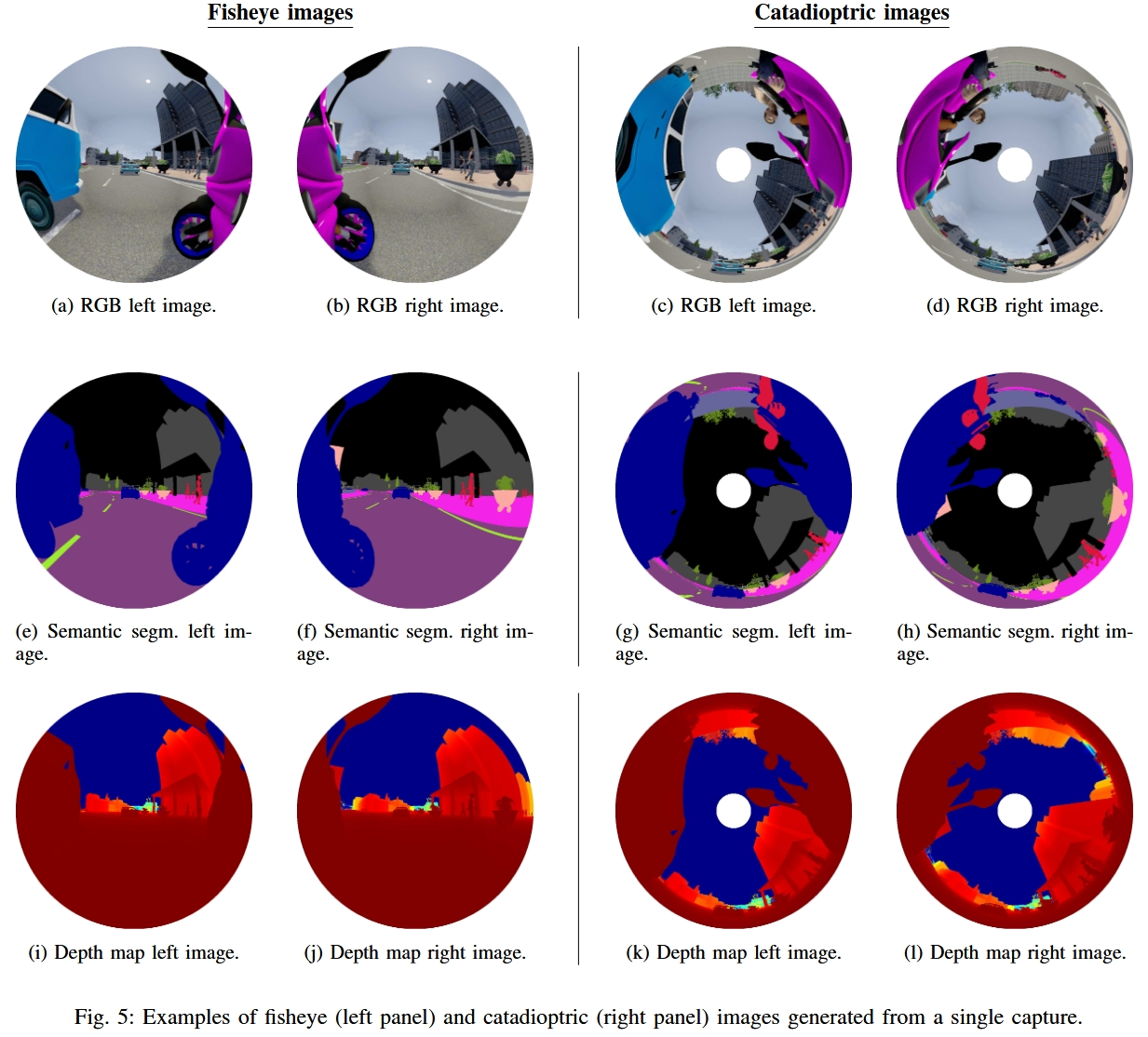
The OmniScape dataset
- ICRA 2020
- 背景
- 全景图像在机器人技术和汽车应用中的效用和好处
- 目前还没有带有语义分割、深度图和动态属性的全景图像数据集
- 提出了一个可以应用于任何模拟器或虚拟环境以生成全景图像的框架
- 展示了所提出框架在两个知名模拟器上的适用性
- CARLA模拟器,这是一个用于自动驾驶研究的开源模拟器
- 《侠盗猎车手V》(Grand Theft Auto V, GTA V),这是一款质量非常高的视频游戏
- 详细解释了生成的OmniScape数据集
- 包括从摩托车前两侧获取的立体鱼眼和猫眼图像
- 包括语义分割、深度图、相机的内在参数以及摩托车的动态参数
- 展示了所提出框架在两个知名模拟器上的适用性
- 关于从模拟器生成数据
- 优点
- 成本较低,可以生成的数据种类多样(如深度图、语义分割或车辆动态属性的详细信息)
- 允许模拟不同的传感器
- 不必处理数据保护和个人隐私的问题
- 目前的数据集
- 含有鱼眼图像的
- CVRG:Classification and tracking of traffic scene objects with hybrid camera systems
- LMS:A dataset providing synthetic and real-world fisheye video sequences
- LaFiDa:LaFiDa - A Laserscanner Multi-Fisheye Camera Dataset
- SVMIS:Spherical Visual Gyroscope for Autonomous Robots Using the Mixture of Photometric Potentials
- Go Stanford:GONet: A Semi-Supervised Deep Learning Approach For Traversability Estimation
- GM-ATCI:Tracking and Motion Cues for Rear-View Pedestrian Detection
- RTH Zurich multi-FoV:Benefit of large field-of-view cameras for visual odometry
- 虚拟的
- SYNTHIA:有 instance 标签但不全
- VEIS(Virtual Environment for Instance Segmentation):有 instance 标签
- GTA V 上生成的
- VIPER: 有 instance 标签但不全
- G2D: from GTA to Data(有开源软件下载)
- GTA5:无 instance 标签
- Unlimited Road-scene Synthetic Annotation (URSA) Dataset
- Driving in the Matrix: Can virtual worlds replace human-generated annotations for real world tasks?
- 含有鱼眼图像的
- 优点
Panoptic Segmentation: A Review
- arxiv 2021
- 没有涉及全景图像
Near-Field Perception for Low-Speed Vehicle Automation Using Surround-View Fisheye Cameras
- ITS 2021
- 背景
- 摄像头是自动驾驶系统中的主要传感器
- 环视摄像系统通常由四个鱼眼镜头组成,具有190°+的视野覆盖范围,围绕车辆全方位聚焦于近场感知
- 提供了这类视觉系统的详细调查,将调查设置在可以分解为四个模块化组件的架构中
- 识别(Recognition)、重建(Reconstruction)、重新定位(Relocalization)和重新组织(Reorganization),称这为4R架构
- 讨论了每个组件如何完成特定方面
- 提出了一个定位论点,即它们可以协同工作形成一个完整的低速自动化感知系统
- 通过展示以往工作的结果以及提出此类系统的架构建议来支持这一论点
Is context-aware CNN ready for the surroundings? Panoramic semantic segmentation in the wild
- TIP 2021
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 语义分割在像素级别统一了大多数导航感知任务,在自动驾驶领域促进了显著的进展
- 现代卷积神经网络(CNN)能够高效准确地执行语义分割,特别是由于它们利用了广泛的上下文信息
- 大多数分割CNN是针对视野有限的针孔图像进行基准测试的
- 语义分割器尚未在具有丰富且独特上下文信息的全景宽视野(FoV)数据上进行全面评估
- 本文
- 提出了一个同时水平和垂直的注意力模块,以利用在全景图中显著可用的宽度和高度上下文先验
- 为了得到适合宽视野图像的语义分割器,我们提出了一个多源全监督学习方案,通过数据蒸馏在训练中覆盖全景领域
- 为了促进当代CNN在全景图像中的评估,我们提出了Wild PAnoramic Semantic Segmentation(WildPASS)数据集,包括来自全球各地的图像,以及不利和无约束的场景
- 实验表明,我们提出的方法使我们的高效架构能够获得显著的准确性提升,在全景图像领域超越了现有技术

Capturing omni-range context for omnidirectional segmentation
- CVPR 2021
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 卷积网络(ConvNets)在语义分割方面表现出色,已成为自动驾驶感知系统中的重要组成部分
- 全景相机提供了全方位的视图,非常适合此类系统
- 大多数用于解析城市环境的分割模型都是在常见的视野狭窄(FoV)图像上运行的
- 为了弥合成像领域之间在FoV和结构分布方面的差距,我们
- 引入了高效的并发注意力网络(ECANets),直接捕获全景图像中固有的长距离依赖性
- 学习到的可以跨越360°图像的基于注意力的上下文先验
- 还通过利用多源和全监督学习来升级模型训练,充分利用来自多个数据集的密集标注和未标注数据
- 在Wild PAnoramic Semantic Segmentation(WildPASS)上提出并广泛评估模型
- 新模型、训练方案和多源预测融合将性能(mIoU)提升到了公共PASS(60.2%)和全新的WildPASS(69.0%)基准测试上的新最先进结果
DensePASS: Dense panoramic semantic segmentation via unsupervised domain adaptation with attention-augmented context exchange
- ITSC 2021
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 智能车辆显然从360°传感器的扩展视野(FoV)中受益
- 绝大多数现有的语义分割训练图像是使用针孔相机捕获的
- 我们通过领域自适应的视角来看待这个问题,并将全景语义分割带到一个设置中,即标记的训练数据来自传统的针孔相机图像的不同分布
- 为全景语义分割的无监督领域自适应任务进行了形式化,其中一个在针孔相机数据的源域上训练的网络被部署在全景图像的不同目标域中,对于该域没有可用的标签
- 收集并公开发布了DENSEPASS - 一个针对全景分割的新型密集标注数据集
- 在跨领域条件下特别构建,用于研究PINHOLE→PANORAMIC转移,并附带从Cityscapes获得的针孔相机训练示例
- DENSEPASS涵盖了标记和未标记的360°图像,标记数据包括19个类别,这些类别明确适合源域(即针孔)数据中的类别
- 为了应对领域偏移的挑战,我们利用了基于注意力机制的最新进展,并构建了一个通用框架,用于基于不同变体的注意力增强领域自适应模块的跨领域全景语义分割
- 我们的框架在局部和全局层面上促进了在领域对应学习时的信息交换,并提高了两个标准分割网络的领域自适应性能,分别在平均IoU上提高了6.05%和11.26%

Panoramic panoptic segmentation: Towards complete surrounding understanding via unsupervised contrastive learning
- IVS 2021
- 《PASS: Panoramic annular semantic segmentation》团队
- 首次提出全景全景分割(panoramic panoptic segmentation)
- 提出了一个框架,允许在标准针孔图像上训练模型,并将学到的特征转移到不同的领域
- 发布了WildPPS:第一个全景全景图像数据集,以促进周围感知的进步
- 使用我们提出的方法,在我们的 WildPPS 数据集上实现了超过5%的显著改进
A survey on deep learning-based panoptic segmentation
- DSP 2022
- 这一小段提到了全景图分割:
- 目前,大多数用于场景分割的图像数据都来自针孔拍摄,这使得大多数分割网络使用具有视场(FoV)图像的公共数据集作为基准。这些传统分割模型在面对全景图像时的准确性大大降低。一些现有的工作已经在全景语义分割方面取得了进展[40,41,81]。[82]首次提出了全景全景分割。[82]使用对比损失和像素传播损失对主干进行无监督预处理,以创建后续图像分割的特征。然后,将预处理的主干插入到一个模型[83]中进行全景全景分割。论文中提出的无监督预处理步骤允许网络将分割目标从传统的针孔图像扩展到具有最小计算开销的宽视场。全景图像克服了视场有限的问题,提供了更完整的真实世界图像,因此在全景图像下进行全景分割可能促进对场景的更深入理解。
High-performance panoramic annular lens design for real-time semantic segmentation on aerial imagery
- Optical Engineering 2022
Omnisupervised omnidirectional semantic segmentation
- ITS 2022
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 现代高效的卷积神经网络(CNN)能够快速准确地执行语义分割,这通常以统一的方式涵盖了智能车辆(IV)所需的独立检测任务
- 大多数当前的语义感知框架都是为针孔相机设计的,并且是针对具有狭窄视场(FoV)图像的公共数据集进行基准测试的
- 当针孔产生的CNN应用于全景图像时,其准确性大幅下降,导致其在周围感知方面不可靠
- 本文提出了一个针对高效CNN的全监督学习框架
- 接了社区中已有的多个异构数据源,绕过了手动标注全景图的劳动密集型过程
- 提高了它们在未见过的全景领域的可靠性
- 作为全监督的,高效的CNN利用了标记的针孔图像和未标记的全景图
- 该框架基于我们专门的集成方法,考虑到全景图像的宽角度和环绕特性,自动生成全景标签用于数据蒸馏
- 实验表明,所提出的解决方案有助于在全景图像领域获得显著的泛化增益
- 我们的方法在高度不受限制的IDD20K和PASS数据集上超越了现有的高效分割器
Transfer beyond the field of view: Dense panoramic semantic segmentation via unsupervised domain adaptation
- ITS 2022
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 自动驾驶车辆显然从360°传感器的扩展视野(FoV)中受益
- 现代语义分割方法严重依赖于标注的训练数据,这些数据对于全景图像来说很少见
- 从领域自适应的角度来看待这个问题,将全景语义分割带到一个设置中,即标记的训练数据来自传统的针孔相机图像的不同分布
- 为全景语义分割的无监督领域自适应任务进行了形式化
- 收集了DENSEPASS - 一个针对全景分割的新型密集标注数据集
- 在跨领域条件下特别构建,用于研究PINHOLE→PANORAMIC领域的转移,并附带从Cityscapes获得的针孔相机训练示例
- 涵盖了标记和未标记的360°图像,标记数据包括19个类别,这些类别明确适合源域(即针孔)数据的类别
- 由于数据驱动的模型特别容易受到数据分布变化的影响,我们引入了P2PDA - 一个用于PINHOLE→PANORAMIC语义分割的通用框架
- 通过不同变体的注意力增强领域自适应模块来解决领域差异的挑战,实现了在输出、特征和特征置信空间的转移
- P2PDA结合了使用注意力头调节的置信值的不确定性感知适应,这些置信值通过存在差异预测的注意力头实时调节
- 我们的框架在学习领域对应关系时促进了上下文交换,并显著提高了以准确性和效率为重点的模型的自适应性能
- 实验验证了我们的框架明显超越了无监督领域自适应和专门的全景分割方法,以及最新的语义分割方法
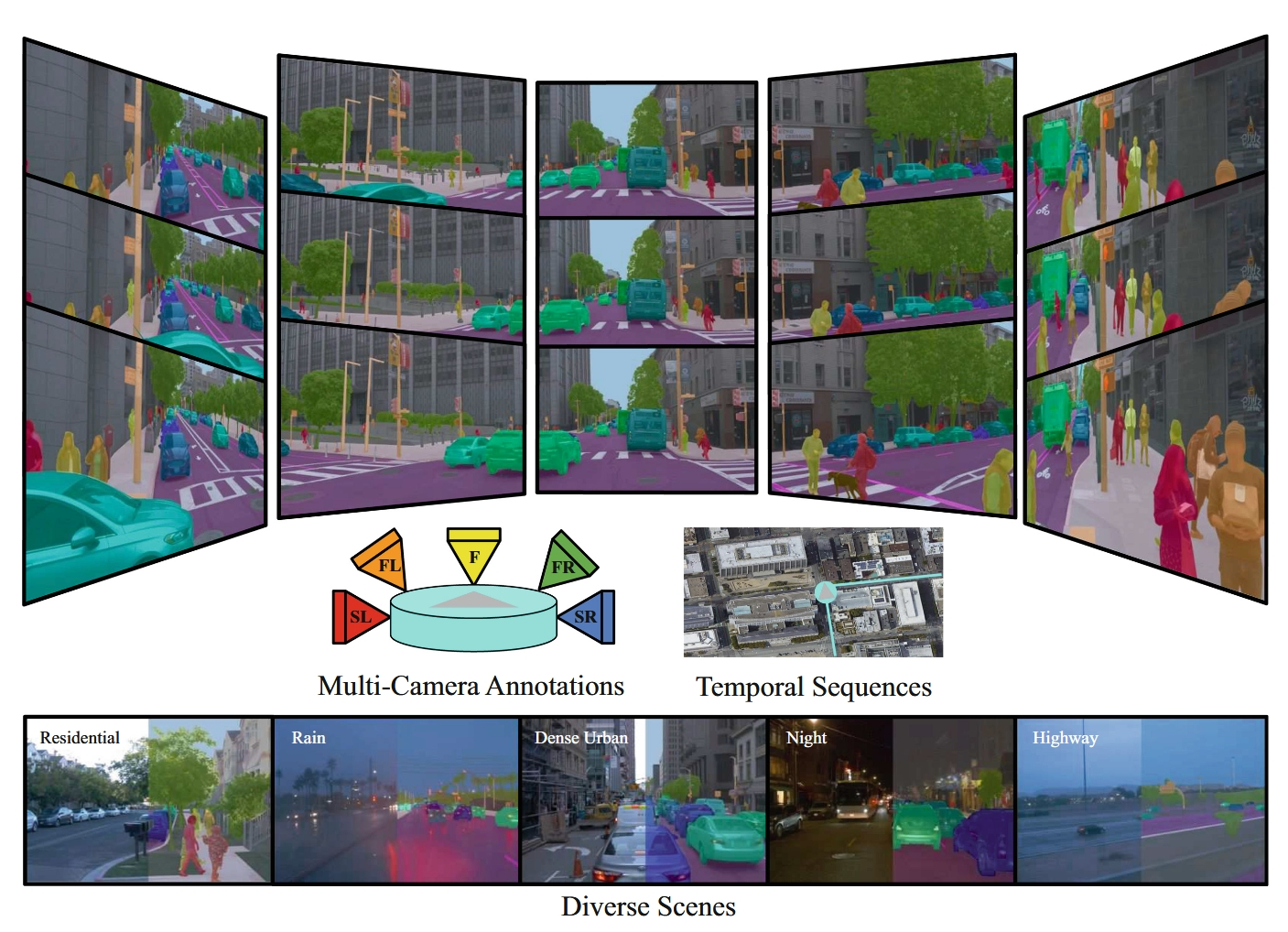
Waymo open dataset: Panoramic video panoptic segmentation
- ECCV 2022
- 背景
- 泛视觉图像分割(panoptic image segmentation)是计算机视觉任务,涉及在图像中找到像素组,并将语义类别和对象实例标识符分配给它们
- 图像分割研究变得越来越受欢迎,研究社区依赖公开可用的基准数据集来推进计算机视觉的最新技术
- 由于密集标记图像的高成本,适合进行泛视觉分割的公开可用真实标签存在短缺
- 高昂的标记成本也使得将现有数据集扩展到视频领域和多相机设置面临挑战
- 我们介绍了Waymo开放数据集:全景视频泛视觉分割
- 使用公开可用的Waymo开放数据集(WOD),利用多样化的相机图像生成我们的数据集
- 我们的标签在视频处理中随时间保持一致,在车辆上安装的多个相机之间保持一致,以实现全景场景理解
- 为28个语义类别和2,860个时间序列提供了标签
- 这些时间序列是由安装在自动驾驶车辆上的五个相机在三个不同的地理位置捕获的,总共有100k张标记相机图像
- 我们的数据集比现有提供视频泛视觉分割标签的数据集大一个数量级
- 进一步提出了一个新的全景视频泛视觉分割基准,并基于DeepLab系列模型建立了几个强基线
Bending reality: Distortion-aware transformers for adapting to panoramic semantic segmentation
- CVPR 2022
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 全景图像以其360°的全方位视角,包含了周围空间的详尽信息,为场景理解提供了丰富的基础
- 形成稳健的全景分割模型,大量昂贵的逐像素注释至关重要
- 这样的注释主要是针对窄角度的针孔相机图像
- 360°全景图中的失真和独特的图像特征分布阻碍了从注释丰富的针孔领域的转移,因此在性能上大打折扣
- 提出了在可变形补丁嵌入(DPE)和可变形MLP(DMLP)组件中学习对象变形和全景图像失真
- 为了克服这一领域差异,将来自针孔和360°环视图像的语义注释结合起来
- 这些组件融入了我们的全景语义分割Transformer模型(Trans4PASS)
- 我们通过生成多尺度原型特征并在无监督领域自适应的互原型适应(MPA)中对齐它们,将针孔和全景特征嵌入中的共享语义联系起来
- 在室内Stanford2D3D数据集上,我们的带有MPA的Trans4PASS保持了与完全监督的最先进水平相当的性能,减少了对超过1400个标记全景的需求
- 室外DensePASS数据集上,我们以14.39%的mIoU打破了最先进的水平,将新的标准设为56.38%。
Semantic segmentation of outdoor panoramic images
- SIVP 2022
- 背景
- 全景摄像头能够在单次拍摄中提供360°的视野。这种全面的视野使它们成为许多计算机视觉应用的首选
- 全景视图通常以等矩形投影的全景图像来表示,这种投影会遭受失真
- 需要对标准摄像头方法进行数学上的修改,以便有效地与全景图像一起使用
- 我们构建了一个能够使用等矩形卷积(equirectangular)处理全景图像中失真的语义分割CNN模型:UNet-equiconv
- 第一个关于真实户外全景图像语义分割的工作
- 实验结果表明,使用具有失真意识的CNN和等矩形卷积可以提高语义分割性能(mIoU增加了4%)
- 还发布了一个像素级标注的户外全景图像数据集,可以用于各种计算机视觉应用,如自动驾驶和视觉定位


Review on Panoramic Imaging and Its Applications in Scene Understanding
- TIM 2022
- 最近的全景图像综述文章
- 背景
- 人类对真实世界场景的感知不再局限于使用小视场(FoV)和低维场景检测设备,全景成像技术作为下一代环境感知和测量的创新智能仪器应运而生
- 全景成像仪器在满足大视场摄影成像需求的同时,还应具备高分辨率、无盲区、小型化和多维智能感知的特点,并能与人工智能方法相结合
- 自由曲面、薄板光学和超表面的最新进展为人类对环境的感知提供了创新的方法,为传统光学成像提供了有希望的新思路
- 在这篇综述中
- 首先介绍了全景成像系统的基本工作原理,描述了各种全景成像系统的架构、特点和功能
- 详细分析了这些技术如何帮助提高全景成像系统的性能
- 详细分析了全景成像在自动驾驶和机器人场景理解中的应用,包括全景语义图像分割、全景深度估计、全景视觉定位等
- 展望了全景成像仪器的未来潜力和研究方向
Deep learning-based panoptic segmentation: Recent advances and perspectives
- IETIP 2023
- 没有涉及全景图像,写得很差
Laformer: Vision Transformer for Panoramic Image Semantic Segmentation
- SPL 2023
- 背景
- 近年来,在语义分割领域取得了巨大进步
- 一般方法针对的是针孔图像,并且在直接应用于全景图像时往往会表现不佳
- 随着全景相机的广泛应用,开发可行的方法来训练它们的实时应用分割模型变得很重要
- 提出了一种使用自我训练(self-training)的新方法
- 为全景图像提出了一个可变形合并模块,通过高效准确地整合不同层次的特征
- 设计了一个新颖的原型适应项,帮助模型更好地学习扭曲对象的类别特征嵌入
- 设计了一个新颖的原型适应项,帮助模型更好地学习扭曲对象的类别特征嵌入
- 我们在DensePASS数据集上达到了58.27%的mIoU分数,并取得了新的最佳结果。
Complementary bi-directional feature compression for indoor 360° semantic segmentation with self-distillation
- WACV 2023
- 背景
- 360°图像的语义分割是场景理解的重要组成部分,因为它们提供了丰富的周围信息
- 基于水平表示的方法优于基于投影的解决方案,因为通过在垂直方向压缩球面数据,可以有效地消除失真
- 这些方法忽略了失真分布先验,并且受限于不平衡的感受野
- 例如,感受野在垂直方向上足够,在水平方向上不足
- 另一种方向压缩的垂直表示可以提供隐式的失真先验并扩大水平感受野
- 本文中,我们结合了这两种不同的表示,并提出了一种新颖的360°语义分割解决方案
- 我们的网络包括三个模块:特征提取模块、双向压缩模块和集成解码模块
- 首先,我们从全景图中提取多尺度特征
- 然后,设计了一个双向压缩模块,将特征压缩成两种互补的低维表示,这些表示提供内容感知和失真先验
- 此外,为了促进双向特征的融合,我们在集成解码模块中设计了一种独特的自我蒸馏策略,以增强不同特征之间的交互,并进一步提高性能
- 实验(在Stanford 2D3DS上进行)结果表明,我们的方法在定量评估上超越了最先进的解决方案,同时在视觉表现上展现了最佳性能。
Single Frame Semantic Segmentation Using Multi-Modal Spherical Images
- WACV 2024
- 背景
- 研究界对提供360°方向视角的全景图像表现出了极大的兴趣
- 可以输入多种数据模态,并利用互补的特性,以便根据语义分割进行更健壮和丰富的场景解释
- 现有的研究大多集中在针孔RGB-X语义分割上
- 提出了一种基于 transformer 的跨模态融合架构,以弥合多模态融合和全景场景感知之间的差距
- 采用失真意识模块来解决由等矩形表示引起的极端目标变形和全景失真问题
- 在合并特征之前进行跨模态交互,以校正特征和交换信息,以便为双模态和三模态特征流传达长期上下文
- 在使用三种室内全景视图数据集(Stanford2D3DS, Structured3D, Matterport3D)的四种不同模态类型的组合进行彻底测试时,我们的技术实现了最先进的mIoU性能
Behind every domain there is a shift: Adapting distortion-aware vision transformers for panoramic semantic segmentation
- TPAMI 2024
- 《PASS: Panoramic annular semantic segmentation》团队
- 背景
- 全景图像中的图像失真和物体变形
- 360°图像中缺乏语义注释
- 为了解决这些问题
- 我们提出了升级版的全景语义分割Transformer,即Trans4PASS+
- 配备了可变形补丁嵌入(DPE)和可变形MLP(DMLPv2)模块,用于处理物体变形和图像失真
- 无论是在适应之前还是之后,以及在浅层或深层水平
- 我们通过伪标签校正增强了互原型适应(MPA)策略,用于无监督领域自适应全景分割
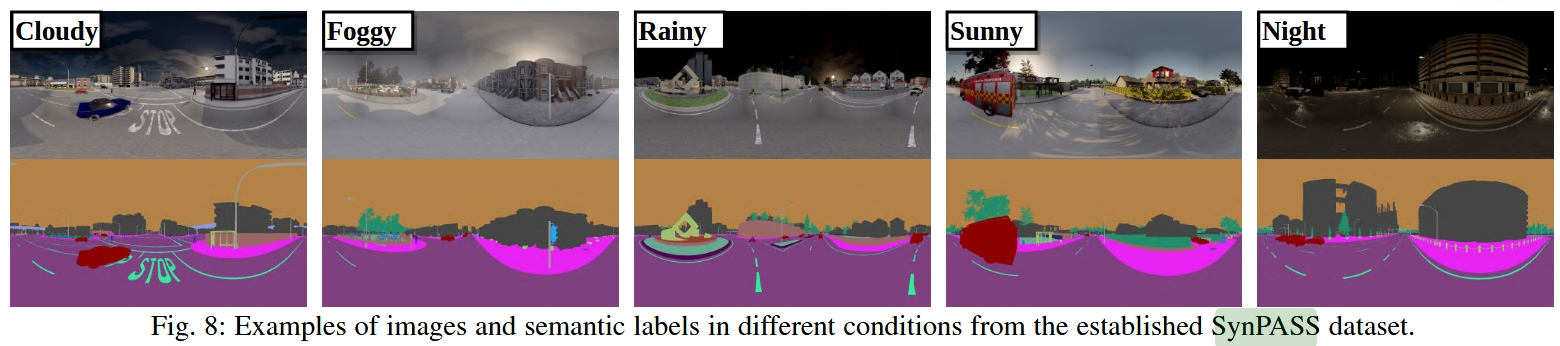
- 除了针孔到全景(PIN2PAN)适应,我们创建了一个新的数据集(SynPASS),包含9,080张全景图像
- 我们提出了升级版的全景语义分割Transformer,即Trans4PASS+
- 我们进行了广泛的实验,涵盖了室内和室外场景,每个场景都通过PIN2PAN和SYN2REAL方案进行了研究
- Trans4PASS+在四个领域自适应全景语义分割基准测试中取得了最先进的性能
全景图/视频 —— SOD
Distortion-Adaptive Salient Object Detection in $360^{\circ}$ Omnidirectional Images
- TVCG 2020
- 北航, 虚拟现实技术与系统国家重点实验室,Jia Li, Jinming Su, Changqun Xia
- 背景
- 基于图像的显著对象检测(SOD)在过去几十年中已被广泛研究
- 由于缺乏具有像素级注释的数据集,360°全景图像上的SOD研究较少
- 本文提出了一个基于360°图像的SOD数据集(360SOD),该数据集包含500张高分辨率的等矩形图像
- 我们从五个主流的360°视频数据集中收集了具有代表性的等矩形图像,并以自由视点的方式手动为这些图像上的所有对象和区域注释了精确的遮罩
- 这是第一个公开可用的360°场景显著对象检测数据集
- 通过观察这个数据集,我们发现投影失真、大规模复杂场景和小尺寸显著对象是最突出的特征
- 受此启发,本文提出了一个基于等矩形图像的SOD基线模型
- 我们构建了一个失真适应模块来处理等矩形投影引起的失真
- 引入了一个多尺度上下文集成块,用于感知和区分全景场景中的丰富场景和对象
- 整个网络以深度监督的方式组织成渐进式
- 验结果表明,所提出的基线方法在360°SOD数据集上超越了表现最佳的现有方法
- 所提出的基线方法和其他方法在360°SOD数据集上的基准测试结果表明,所提出的数据集非常具有挑战性

A FIXATION-BASED 360◦ BENCHMARK DATASET FOR SALIENT OBJECT DETECTION
- ICIP 2020
- 背景
- 全景内容中的注视点预测(Fixation Prediction, FP)随着虚拟现实(Virtual Reality, VR)应用的蓬勃发展而得到了广泛的研究
- 视觉显著性领域的另一个问题——显著对象检测(Salient Object Detection, SOD)——在360°(或全向)图像中的探索却相对较少
- 缺乏具有像素级注释的真实场景数据集
- 为了解决这一问题
- 我们收集了107幅具有挑战性场景和多个对象类别的等矩形全景图
- 基于注视点预测与显式显著性判断之间的一致性,我们在真实人类眼动追踪图的指导下,进一步手动标注了1,165个显著对象,并为这些对象在收集到的图像上提供了精确的遮罩
- 接着,我们采用了基于多重立方体投影的微调方法,对六种最先进的SOD模型在提出的基于注视点的360°图像数据集(F-360iSOD)上进行了基准测试
- 实验结果表明,现有方法在全景图像的SOD应用中存在局限性,这表明所提出的数据集具有挑战性

FANet: Features Adaptation Network for 360 Omnidirectional Salient Object Detection
- SPL 2020
- 背景
- 显著对象检测(SOD)在360°全景图像中已成为一个引人注目的问题,这得益于价格合理的360°相机的普及
- 我们提出了一种特征适应网络(FANet),以可靠地突出显示360°全景图像中的显著对象
- 为了利用卷积神经网络的特征提取能力并捕获全局对象信息,我们同时将等矩形360°图像和相应的立方图360°图像输入到特征提取网络(FENet),以获得多级等矩形和立方图特征
- 此外,我们通过投影特征适应(PFA)模块在FENet的每个级别融合这两种特征,以自适应地选择这两种特征
- 后,我们通过多级特征适应(MLFA)模块将不同级别的初步适应特征结合起来,该模块自适应地加权这些不同级别的特征,并产生最终的显著性图
- 实验表明,我们的FANet在360°全景SOD数据集(360−SOD, F-360iSOD)上超越了最先进的方法
Stage-wise salient object detection in 360° omnidirectional image via object-level semantical saliency ranking
- TVCG 2020
- 北航, 虚拟现实技术与系统国家重点实验室,Guangxiao Ma, Shuai Li
- 背景
- 二维图像的显著对象检测(SOD)已经被广泛研究,而基于360°全景图像的SOD得到的关注度较少,并且存在三个主要的瓶颈限制了其性能
- 首先,目前可用的训练数据不足以训练360°SOD深度模型
- 其次,360°全景图像中的视觉失真通常导致360°图像和二维图像之间的特征差异很大;因此,分阶段训练——一种广泛使用的解决训练数据短缺问题的方案,在进行360°全景图像的SOD时变得不可行
- 第三,现有的360°SOD方法采用了多任务方法,同时执行显著对象定位和类似分割的显著性细化,面对着极其大的问题领域,使得训练数据短缺的困境更加严重
- 二维图像的显著对象检测(SOD)已经被广泛研究,而基于360°全景图像的SOD得到的关注度较少,并且存在三个主要的瓶颈限制了其性能
- 为了解决所有这些问题,本文将360°SOD划分为多阶段任务,其关键理念是将原始复杂的问题领域分解为顺序的简单子问题,这些子问题只需要小规模的训练数据
- 同时,我们学习如何对“object level 语义显著性”进行排名,以准确定位显著的视点和对象
- 为了缓解训练数据短缺问题,我们发布了一个名为360-SSOD的新数据集
- 包含1,105张360°全景图像,并手动标注了对象级显著性真实情况,其语义分布比现有数据集更加平衡
- 已经将提出的方法与13种最先进方法进行了比较,所有定量结果都证明了性能的优越性
- 为了缓解训练数据短缺问题,我们发布了一个名为360-SSOD的新数据集

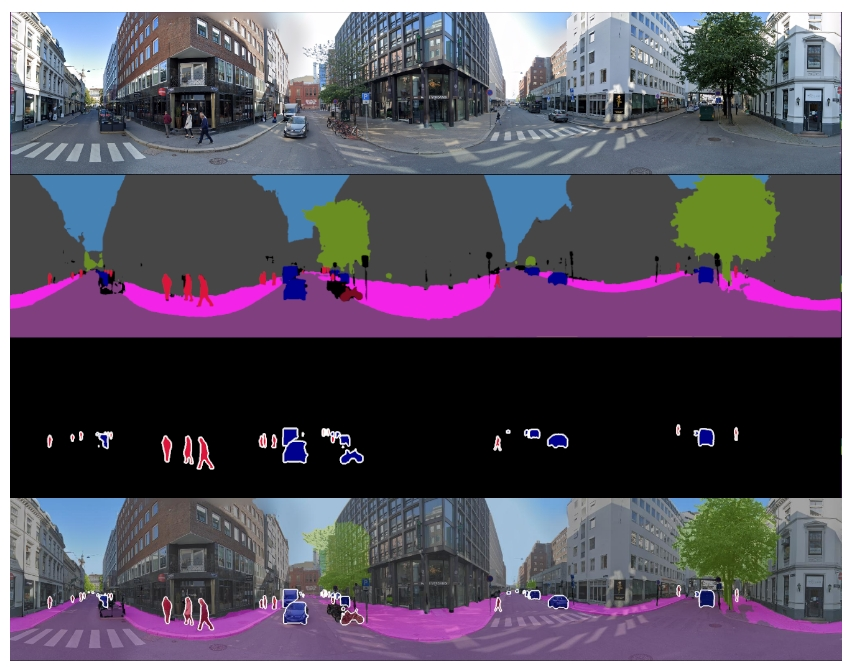
ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos
- Arxiv 2021
- 背景
- 探索人类在动态全景场景中关注的内容对于许多基础应用非常有用,包括零售业中的增强现实(AR)、AR支持的招聘和视觉语言导航
- 我们提出了PV-SOD,这是一项新任务,旨在从全景视频中分割显著对象
- 与现有的注视点/对象级显著性检测任务不同,我们专注于声音诱发的显著对象检测(SOD),其中显著对象是根据声音诱发的眼动进行标记的
- 我们收集了第一个大规模数据集,名为ASOD60K,其中包含带有六级层级注释的4K分辨率视频帧
- 每个序列都标有其超类/子类,每个子类中的对象进一步用人类眼动注视点、边界框、对象级/实例级遮罩和相关属性(例如,几何失真)进行了注释
- 我们系统地在ASOD60K上对11种代表性方法进行了基准测试,并得出了几个有趣的发现
View-Aware Salient Object Detection for 360∘ Omnidirectional Image
- TM 2022
- 北航, 虚拟现实技术与系统国家重点实验室,Junjie Wu , Changqun Xia
- 背景
- 360◦场景中基于图像的显著目标检测对于理解和应用全景信息具有重要意义
- 然而,由于缺乏大型、复杂、高分辨率和良好标记的数据集,360◦isod的研究还没有得到广泛的探索
- 我们构建了一个大规模的360◦等值域数据集,该数据集包含了不低于2K分辨率的丰富全景场景,是目前已知的最大的360◦等值域数据集
- 通过对数据的观察,我们发现现有的方法在全景场景中面临着三个显著的挑战:不同的失真程度、不连续的边缘效应和可变的对象比例
- 受人类观察过程的启发,我们提出了一种基于样本自适应视图转换器(SAVT)模块的视点感知显著目标检测方法
- 子模块视图转换器(VT)包含三个基于不同类型变换的变换分支,以学习不同视图下的各种特征,并提高模型对变形、边缘效果和对象尺度的特征容忍度
- 子模块样本自适应融合(SAF)是根据不同的样本特征调整不同变换支路的权重,使变换后的增强特征融合得更好
- 20种最先进的isod方法的基准测试结果表明,所构建的数据集是非常具有挑战性的
- 详尽的实验验证了所提出的方法是实用的,并且优于目前最先进的方法

Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information
- ETCI 2023
- 背景
- 近年来,针对二维图像的显著目标检测技术得到了广泛的研究
- 然而,由于场景的复杂性和几何失真的存在,360°超视场的研究在大视场范围内还很欠缺
- 本文提出了一种360°全方位图像目标定位的分阶段解决方案,该方案综合考虑了RGB图像和互补的对象级语义(OLS)信息对目标定位的影响
- 为了有效地连接两种类型的特征,提出了一种新颖的多层特征融合和渐进聚集网络(MFFPANet),用于准确检测360°全方位图像中的显著目标
- 该网络主要由动态互补特征融合(DCFF)模块和渐进多尺度特征聚集(PMFA)模块组成
- 首先,OLS和RGB图像共享同一个主干网络进行联合学习,DCFF模块动态整合主干网络的层次特征
- 此外,PMFA模块包括多个级联的特征集成模块,这些模块通过深度监管逐步地集成多尺度的特征
- 为了有效地连接两种类型的特征,提出了一种新颖的多层特征融合和渐进聚集网络(MFFPANet),用于准确检测360°全方位图像中的显著目标
- 实验结果表明,该算法在两个360°SOD数据库(360SOD、360SSOD)上取得了较好的性能
PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection
- ACMMCC 2023
- 首篇全景视频SOD
- 背景
- 在360°全景真实动态场景中进行目标级视听显著检测,对于探索和建模沉浸式环境中的人的感知,以及在教育、社交网络、娱乐和培训等领域的虚拟、增强和混合现实应用的开发具有重要意义
- 提出了一项新的任务—全景视听显著目标检测(PAV-SOD),旨在从反映现实生活场景的360°全景视频中分割出最能抓住人类注意力的目标
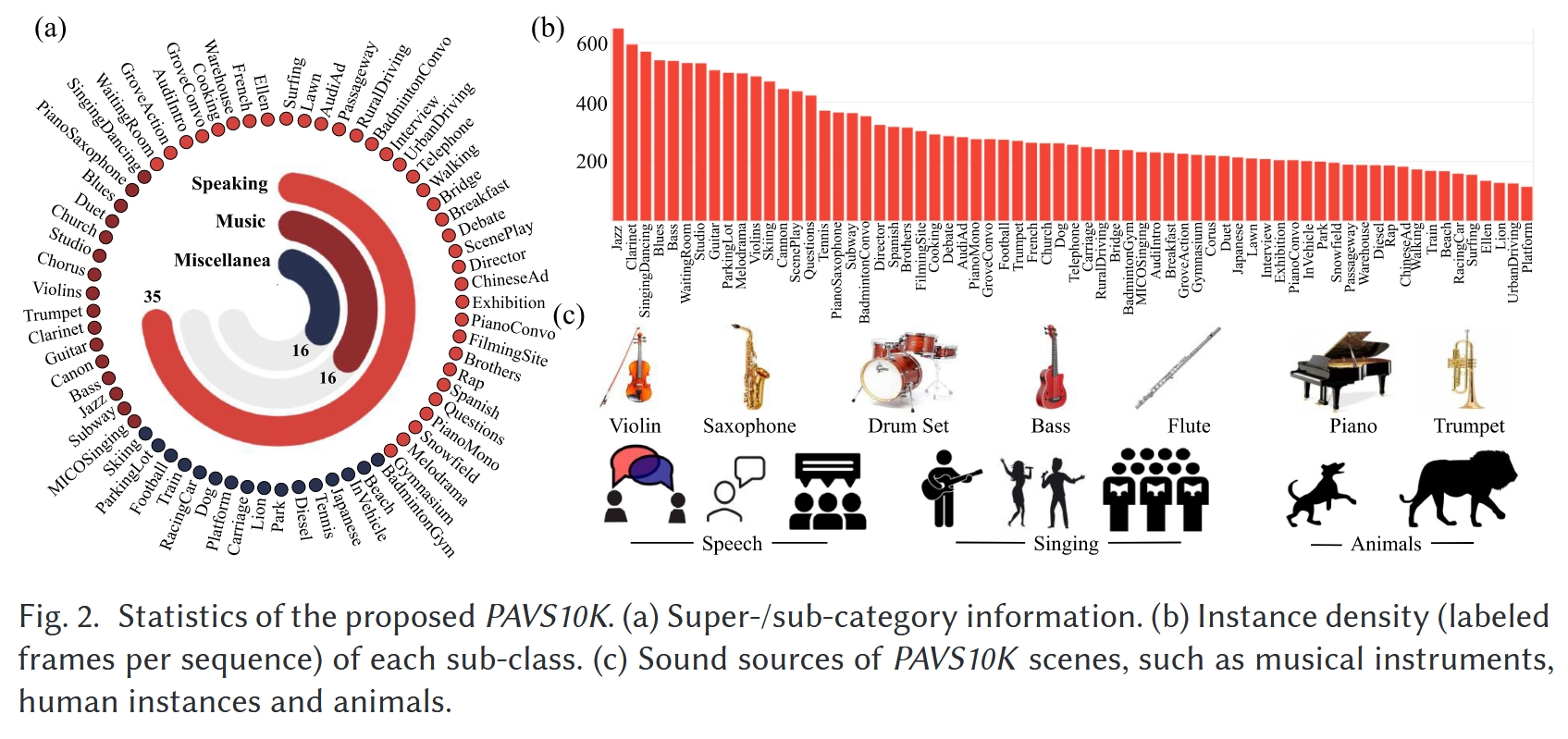
- 我们收集了PAVS10K,这是第一个用于视听显著对象检测的全景视频数据集
- 包括67个4K分辨率的等长方形视频,每个视频带有分层的场景类别和相关属性,这些标签描述了进行PAV-SOD的具体挑战
- 10,465个均匀采样的视频帧,其中包含手动注释的对象级和实例级像素掩码
- 从粗到细的注释允许对PAV-SOD建模进行多角度分析
- 我们收集了PAVS10K,这是第一个用于视听显著对象检测的全景视频数据集
- 基于我们的PAVS10K,我们进一步系统地基准了13种最先进的显著对象检测(SOD)/视频对象分割(VOS)方法
- 还提出了一种新的基线网络,该网络利用了360°视频帧的视觉和音频线索,并使用了一种新的条件变分自动编码器(CVAE)
- 基于CVAE的视听网络CAV-Net由时空视频分割网络、卷积音频编码网络和视听分布估计模块组成。因此,我们的CAV-Net优于所有竞争模型,并能够估计PAVS10K中的任意不确定性
- 通过广泛的实验结果,我们获得了一些关于PAV-SOD挑战的发现和对PAV-SOD模型可解释性的见解

Panoramic Video Salient Object Detection with Ambisonic Audio Guidance
- AAAI 2023
- 背景
- 视频显著目标检测作为计算机视觉的一个基本问题,在过去的十年中得到了广泛的研究
- 现有的所有工作都集中在解决二维场景中的VSOD问题
- 随着VR设备的快速发展,全景视频已经成为2D视频的一种有前途的替代方案,可以提供对现实世界的身临其境的感觉
- 在本文中,我们的目标是解决全景视频及其相应的音频的视频显著目标检测问题
- 了有效地进行视听交互,提出了一种配备两个pseudo-siamese视听上下文融合(ACF)块的多模式融合模块
- 配备球面位置编码的ACF块使得3D环境中的融合能够从等长方形帧和双音音频中捕捉像素和声源之间的空间对应
- 实验结果验证了我们提出的组件的有效性,并证明了我们的方法在ASOD60K数据集上取得了最好的性能
Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking
- ACMMM 2024
- 首篇全景视频SOR
- 背景
- 全景视听显著性检测是在360°含有声音的全景视频中分割最吸引注意力的区域
- 为了精确地界定检测到的显著区域并有效模拟人类注意力的转移,我们将这项任务扩展到更细致的实例场景:识别显著对象实例并推断它们的显著性等级
- 在本文中,我们提出了第一个实例级框架,可以同时应用于全景视频中多个显著对象的分割和排序
- 包括一个感知失真的像素解码器来克服全景失真
- 一个顺序视听融合模块来整合视听信息
- 一个时空对象解码器来分离单个实例并预测它们的显著性分数
- 由于缺乏此类注释,我们为PAVS10K基准创建了真实显著性等级
- 实验表明,我们的模型能够在PAVS10K上实现显著性检测和排序任务的最先进性能
- 其他细节
- 声音不是查询,而是作为辅助信息嵌入到视觉特征中
- 另外,由于缺乏排名注释,我们根据多个观察者的注意力转移为PAVS10K数据集提供了真实的显著性排名
疑惑与想法
- SOR 一定需要 full segmentation 数据吗?—— 不是
- 所谓“显著”,应该是下意识的(因此最好用眼动数据定义)
- 输出是 saliency map,然后比较得出排序结果吗?
- SOR领域论文大致分为五类(及其组合)
- 数据集创新
- 真值创新(如何考虑相对显著性)
- 注视点(离散)
- 显著性图(连续)
- 注视点转移顺序
- 特定算法产生
- 损失函数创新
- 评价指标创新
- 方法创新
- 逐物体/逐像素(被淘汰)
- 多任务学习(较复杂且不易优化)
- 考虑上下文
- 考虑同一图像中对象间相互作用
- 考虑纹理、形状
- 考虑不同图像中显著性水平相同的物体的共性
- 图神经网络
- 除了最早两篇论文,为什么 SOR 领域主要是中国人在做?
- 目前对 轨迹预测 与 显著性 的研究,感觉有点互为因果了
- 对全景图而言:头部轨迹 -> 头部固视点 -> 高斯核卷积 -> 显著性图,可能需要融合多条头部轨迹的结果
- 同时,也有根据显著性图预测 2D 图像注视点轨迹的工作
- 关于全景图像分割
- 多集中在牙齿分割(医学)、无人驾驶场景分割;很多文章发表在光学期刊上
- 几乎全是 semantic segmentation,过渡到 panoptic segmentation,没有单独的 instance segmentation
- 大多数宽视场语义分割研究工作都必须处理数据稀缺问题
- 对像素级别的语义标签进行注释非常耗费劳动和时间,特别是对于全景图像,因为它们具有更大的畸变、由于宽视场而更复杂,通常还包含更多的小物体
- 研究人员已经明确地将全景分割形式化为一个无监督领域适应问题(domain adaptation problem)或领域泛化问题(domain generalization problem),通过从数据丰富的针孔领域(pinhole domain)转移到数据稀缺的全景领域(panoramic domain)
- 对于领域适应,可以使用标记的针孔数据作为源领域,未标记的全景图像作为目标领域
- 对于领域泛化,只能使用源领域的图像,目标是产生一个在目标领域中健壮、泛化的分割模型
- 很多所谓“全景图”数据集,并不是 360°x180°
- 如果要研究全景图 SOR,应该不能用 semantic 分割数据集,至少是 instance 级别
- 标注方法
- 从已有的针孔图像数据集合成(需要有多视角)
- 全景图 -> 分割成子图集合 -> 分割模型 -> 子图的标注 -> 合成(应该不能全采用这个方法)
- 问题是,如果用来监督模型的真值是这样生成的,那为什么不直接用这种方法?(论文《Semantic segmentation of outdoor panoramic images》中rebuttal说,实验发现这种方法有助于 在FOV图像上预训练的模型 更好适应 全景图)
- 手工标注
