图像
| 数据库 | 使用的论文 | 创建的论文 | 图像数目 | 标注类型 | 建库过程 | 其它 |
|---|---|---|---|---|---|---|
| PASCAL-S (应该优于IS与增强的Bruce) |
Revisiting Salient Object Detection: Simultaneous Detection, Ranking, and Subitizing of Multiple Salient Objects CVPR 2018 |
The Secrets of Salient Object Segmentation CVPR 2014.6 |
训练集:425 测试集:425 |
凝视点+完整分割图+实例显著性排序(通过多人点击定义) | 来自PASCAL VOC 2010 分割任务的验证集 每个分割的显著性值为其获得的点击总数除以参与标注的受试者人数 |
The Secrets of Salient Object Segmentation (gatech.edu) (网站打不开) 缺点:图像规模较小 |
| IS | The Secrets of Salient Object Segmentation CVPR 2014.6 |
Visual saliency based on scale-space analysis in the frequency domain TPAMI 2013.4 |
235张,分为6类: 1) 50 张具有大显著区域的图像;2) 80 张具有中等显著区域的图像;3) 60 张具有小显著区域的图像;4) 15 张背景杂乱的图像;5) 15 张具有重复干扰物的图像;6) 15 张同时具有大和小显著区域的图像。 |
凝视点+显著物体标注 | 使用 Google 以及最近的文献收集 | http://www.cim.mcgill.ca/∼lijian (网站打不开) |
| 增强的Bruce | The Secrets of Salient Object Segmentation CVPR 2014.6 |
What stands out in a scene? A study of human explicit saliency judgment Vision Research 2013.10 |
原生Bruce数据集: 120张彩色室内外图像,凝视点数据 Neil D. B. Bruce (inria.fr) |
凝视点+单一最显著物体掩码 | 观察者需要在最显眼的物体周围画一个多边形。我们主要关注在图像中选择单个显著物体的情况。观察者的标注要求不能太宽泛(笼统)或太紧凑(具体)围绕物体。 | 未找到地址 超过 30% 的分割图完全为空 |
| COCO-SalRank (声称好于PASCAL-SR) |
Relative Saliency and Ranking: Models, Metrics, Data and Benchmarks TMAPI, 2019 |
Relative Saliency and Ranking: Models, Metrics, Data and Benchmarks TMAPI, 2019 |
版本1(有噪):训练集:7047 测试集:3363 版本2(精炼):训练集:3052 测试集:1381 |
模拟注视点+实例级掩码 | 从SALICON数据集获得模拟眼动数据,从MS COCO获得实例级掩码数据,通过一系列算法(见论文)得到排名真值 | 实例总数限制为最多五个 没有实例被分配相同的排名值 缺点:使用复杂的人为设计规则来确定显著实例 |
| 未命名 (ASR) (ASSR) |
Inferring Attention Shift Ranks of Objects for Image Saliency CPVR 2020 Salient object ranking with position-preserved attention ICCV 2021 Bidirectional object-context prioritization learning for saliency ranking CVPR 2022 Partitioned Saliency Ranking with Dense Pyramid Transformers ACMMM 2023 Domain Separation Graph Neural Networks for Saliency Object Ranking CVPR 2024 |
Inferring Attention Shift Ranks of Objects for Image Saliency CPVR 2020 |
训练集:7646 验证集:1436 测试集:2418 包含 78 个物体类别,每张图像中的平均物体数量约为 11 个,前 5 个视觉上最显著的实例拥有从 1 到 5 的唯一排序顺序 |
模拟注视点+实例级掩码+显著性排名(通过注视点转移顺序定义) | 从MS COCO和SALICON的训练、验证集构建,基于前五个不重复访问的不同对象的注视顺序来考虑显著性排序 | SirisAvishek/Attention_Shift_Ranks (github.com) 使用至少包含两个显著对象的图像 缺点:关注注意力转移;为每张图像中的固定数量物体生成注释,而不是区分显著物体和非显著物体 |
| 未命名 (IRSR) |
Instance-level relative saliency ranking with graph reasoning TPAMI 2021 Bidirectional object-context prioritization learning for saliency ranking CVPR 2022 Partitioned Saliency Ranking with Dense Pyramid Transformers ACMMM 2023 Domain Separation Graph Neural Networks for Saliency Object Ranking CVPR 2024 |
Instance-level relative saliency ranking with graph reasoning TPAMI 2021 |
训练集:6,059 测试集:2,929 |
实例级掩码+显著性排名(通过实例掩码中显著性最大值定义,相当于注视时间) | 1. 从 MS COCO 数据集中找到 15,000 张 SALICON 图片,提取其实例分割掩码 2. 5名研究生人工选择和标注,按给定规则排除不合适的图像 3. 利用SALICON 数据集提供的显著性图(而不是注视点),根据每个实例掩码中的最大显著性值对标记的显著物体进行排名 |
|
| CAM-FR (伪装物体) |
Simultaneously Localize, Segment and Rank the Camouflaged Objects CVPR 2021 |
Simultaneously Localize, Segment and Rank the Camouflaged Objects CVPR 2021 |
训练集:2000(1711来自COD10K-CAM+289来自CAMO) 测试集:280(238来自COD10K-CAM+42来自CAMO) |
分割掩码+注视点+显著性排名 (排名 0 :背景 排名 1 :最困难 排名 2:中等 排名 3 :最简单) |
1. 对现有伪装目标检测数据集 CAMO和 COD10K中的一些图像进行重新标注 2. 眼动追踪伪装物体检测数据集,得到基于检测延迟(6名观察者注意到每个伪装实例的时间的中位数)的排序数据集 3. 如果超过一半的观众忽略了该实例,将其视为难样本,搜索时间设置为 1;否则删除相应观众的值,从剩余的检测延迟中计算中位数 |
JingZhang617/COD-Rank-Localize-and-Segment (github.com) |
| 未命名 | Rethinking Object Saliency Ranking - A Novel Whole-Flow Processing Paradigm TIP 2023 |
Rethinking Object Saliency Ranking - A Novel Whole-Flow Processing Paradigm TIP 2023 |
训练集:10,000 验证集:1,200 测试集:3,800 |
从注视点利用算法生成真值 | 利用论文提出的RA-SRGT真值生成方法,从SALICON的注视点数据中标注 | |
| RGBD NYU-rank dataset (3D、室内图像) |
RGB-D salient object ranking based on depth stack and truth stack for complex indoor scenes PR 2023 |
RGB-D salient object ranking based on depth stack and truth stack for complex indoor scenes PR 2023 |
训练集:1160 测试集:289 |
RGB图+深度图+实例分割标签+显著性排序真值 | 1. 基于NYU Depth-v2数据集,由13名标注者根据注意到对象的顺序对每张图像中的显著对象进行标记 2. 不限制标注者可以标注的物体数量 3. 将标注次数超过 6 次的物体视为显著物体 4. 每个标注者对第一个标注的显著物体给予 1 分,之后标注的显著物体的分数每次减少 10% 5. 将不同标注者对同一实例的标注分数汇总,然后将不同实例的汇总分数在每张图像内进行排序 |
|
| SalSOD | HyperSOR: Context-Aware Graph Hypernetwork for Salient Object Ranking TPAMI 2024 |
HyperSOR: Context-Aware Graph Hypernetwork for Salient Object Ranking TPAMI 2024 |
4,373 张图像(133,338 个对象) 训练集:测试集=2:1 |
语义分割掩码和边界框+显著性值和显著性排名+场景图标注 | COCO收集多场景图像,SALICON+SAM方法得到显著性图,VG标注场景图,41名志愿者判断、修改 | MinglangQiao/SalSOD: Database for “HyperSOR: Context-aware graph hypernetwork for salient object ranking”, TPAMI 2024 (github.com) |
| SIFR | Advancing Saliency Ranking with Human Fixations - Dataset, Models and Benchmarks CVPR 2024 |
Advancing Saliency Ranking with Human Fixations - Dataset, Models and Benchmarks CVPR 2024 |
训练集:6701 测试集:1688 |
注视点+实例分割掩码+显著性排序真值(由注视点数量定义) | 1. 使用从 MS-COCO 中挑选的至少包含三个物体的图像,计算多个用户在每个场景中的眼动注视时间 2. 使用眼动跟踪系统进行“自由浏览”任务,观察8名参与者的观看习惯,凝视记录的过程持续了六个月,移除所有时长少于 200 毫秒的注视,移除了每位参与者首次捕获的注视点 3. 10名参与者对任何注释质量差或缺失的分割进行重新注释 |
EricDengbowen/QAGNet: Official repository for CVPR 2024 paper “Advancing Saliency Ranking with Human Fixations: Dataset, Models and Benchmarks”. (github.com) 对给定场景中可能的显著实例数量不设上限 |
视频
| 数据库 | 使用的论文 | 创建的论文 | 规模 | 标注类型 | 建库过程 | 其它 |
|---|---|---|---|---|---|---|
| RVSOD | Ranking Video Salient Object Detection ACMMM 2019 |
Ranking Video Salient Object Detection ACMMM 2019 |
300多个视频,共10,000张帧图像(每5帧标注一张) | 实例级掩码+注视点+显著性排名真值 | 1. 基于现有的眼动追踪数据集 UCF sports 和 HOLLYWOOD2 进行标注,表现相似且不适合显著目标检测的视频序列被移除 2. 眼动追踪点的数量用于确定每个目标的显著程度 |
缺点: 1. 80%以上的眼动注视集中在人的身上 2. 一些视频仅包含单一显著目标(即没有显著性排名) 3. 仅从运动视频和电影中选取,缺乏多样性 |
| DAVSOR | Rethinking Video Salient Object Ranking Arxiv 2022 |
Rethinking Video Salient Object Ranking Arxiv 2022 |
128个视频,17,584张帧图像 包含动物、车辆和人类活动等类别 训练集:7,403张 测试集:10,181张 |
眼动图、实例级掩码、显著性排名真值 | 1. 从DAVSOD收集视频、对应的眼动图、显著目标掩码 2. 请了5位人工标注者根据 Fan et al. (2019) 的眼动点和显著实例注释对显著性进行排序 |
1. 不需要任何后处理或眼动注视监督 2. 每个视频中都有至少两个具有显著性排名的显著目标 |
全景图
全景图数据库
| 数据库 | 创建日期 | 描述 | 其它 |
|---|---|---|---|
| F-360iSOD | |||
| SUN360 | |||
| YouTube360 | |||
| ODISR |
VQA(Visual Quality Assessment) 数据库
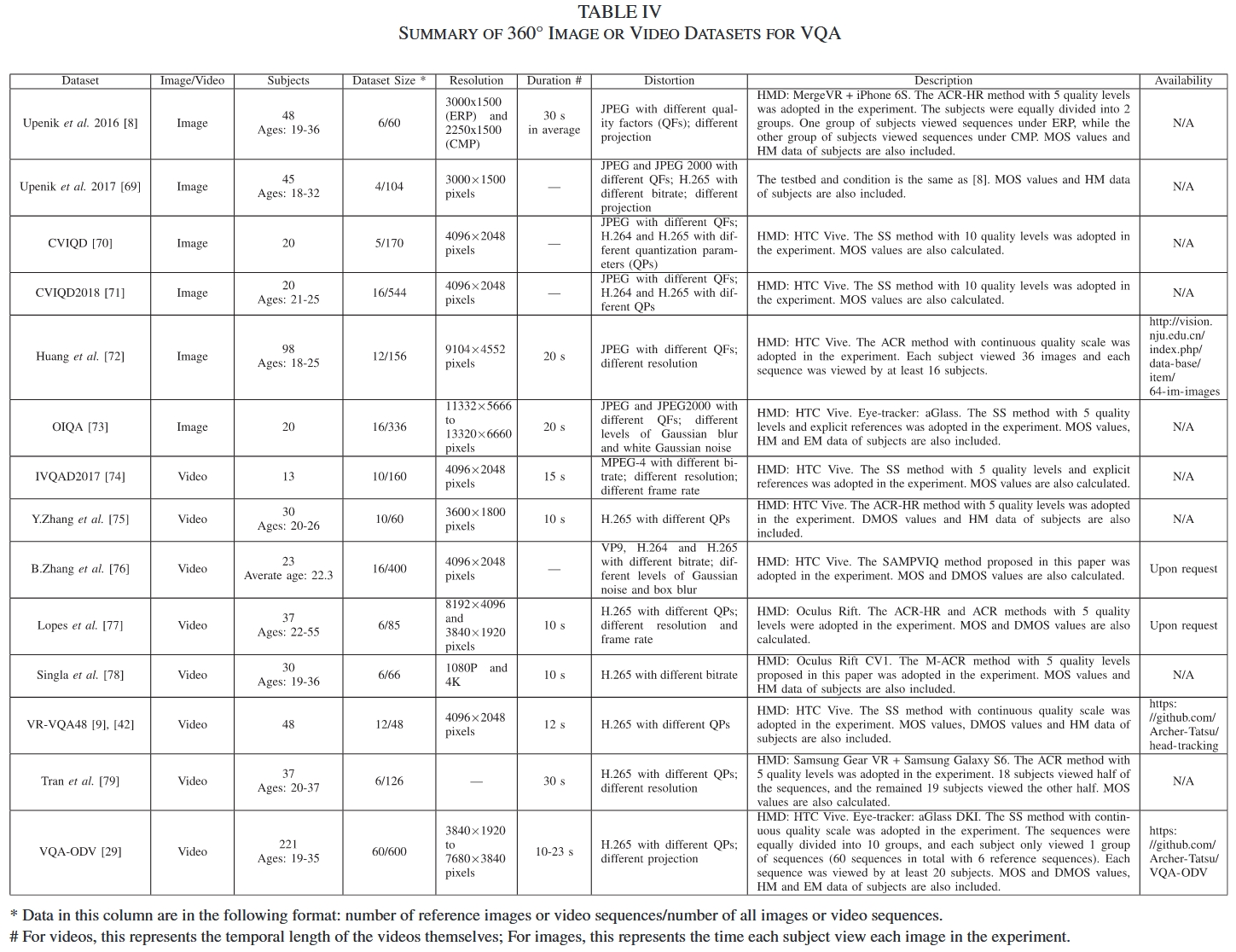
截至 2020,ODI/ODV 的 VQA 数据库(来自《State-of-the-Art in 360° Video_Image Processing - Perception, Assessment and Compression》)
| 数据库 | 使用的论文 | 创建的论文 | 规模 | 标注类型 | 建库过程 | 其它 |
|---|---|---|---|---|---|---|
| IQA-ODI | Spatial Attention-Based Non-Reference Perceptual Quality Prediction Network for Omnidirectional Images ICME 2021 TVFormer: Trajectory-guided Visual Quality Assessment on 360° Images with Transformers ACMMM 2022 |
Spatial Attention-Based Non-Reference Perceptual Quality Prediction Network for Omnidirectional Images ICME 2021 |
1080张 (120张参考图像+960张受损图像) |
头部轨迹+人类主观评分 | 1. 所有参考图像的分辨率为8K(7680 × 3840像素),采用等距矩形投影(ERP)格式;涵盖了人类、风景和自然等广泛的内容类别 2. 考虑了两种类型的损伤:压缩级别和投影模式 3. 受试者200人(138男62女),分为10组,每组观看108张全景图像(每组12张参考图像和96张受损图像) 4. 使用HTC Vive作为媒体播放器,每张图片观看20s,根据质量给出主观评分 |
https://github.com/yanglixiaoshen/SAP-Ne |
Attention 数据库 / 显著性数据库
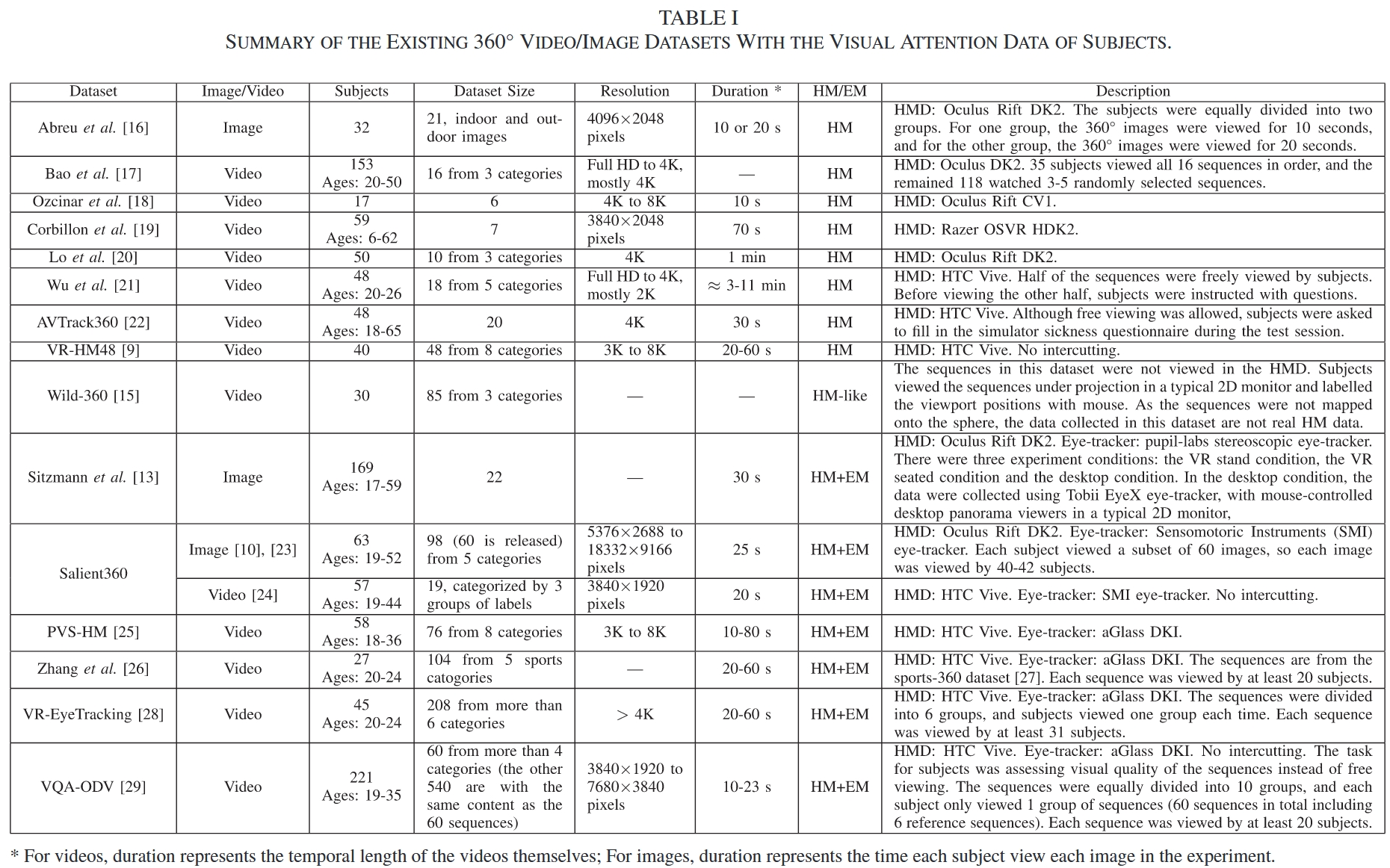
截至 2020,ODI/ODV 的 attention 数据库(来自《State-of-the-Art in 360° Video_Image Processing - Perception, Assessment and Compression》)
截至 2021,ODI/ODV 的 attention 数据库(来自《Saliency Prediction on Omnidirectional Image With Generative Adversarial Imitation Learning》)

| 数据库 | 使用的论文 | 创建的论文 | 规模 | 标注类型 | 建库过程 | 其它 |
|---|---|---|---|---|---|---|
| AOI | Saliency Prediction on Omnidirectional Image With Generative Adversarial Imitation Learning TIP 2021 MC2 |
Saliency Prediction on Omnidirectional Image With Generative Adversarial Imitation Learning TIP 2021 MC2 |
全景图:600 训练集:500 测试集:100 |
head fixations + eye fixations (也能提取 head saccades) |
1. 从Flickr 收集,分辨率范围从4,000 × 2,000到24,028 × 12,014,均以等距矩形格式和最大分辨率下载,包括城市风光、自然风景、室内场景和人物场景四类 2. 通过HTC Vive和aGlass设备获取受试者的头部运动(HM)和眼动(EM)数据 3. 共30名受试者(11男19女),600张图被随机且均等地分为两组,受试者在不同的日期观看,每张图观看22s |
yanglixiaoshen/SalGAIL: Saliency Prediction on Omnidirectional Image with Generative Adversarial Imitation Learning (TIP 2021) (github.com) |
| HTRO | Hierarchical Bayesian LSTM for Head Trajectory Prediction on Omnidirectional Images TPAMI 2022 MC2 |
Hierarchical Bayesian LSTM for Head Trajectory Prediction on Omnidirectional Images TPAMI 2022 MC2 |
全景图:1080 训练集:900 测试集:180 头部轨迹:21600 |
头部轨迹(head trajectories = head fixations + head saccades) | 1. 所有的ODIs都具有8k分辨率,即8,000 × 4,000像素;涵盖了多种内容类型,包括人物、室内场景、风景和自然景观 2.20名受试者(12男8女),使用HTC Vive作为头戴式显示器 3. 分两天进行,每天每名受试者观看540张ODIs,每幅观看22s 4. 如果HM样本的速度小于18度/秒且持续时间大于500毫秒,则该样本属于头部固视点 |
Page not found · GitHub |
得到显著性图的方法:头部轨迹数据库 -> 头部注视点 -> 显著性图
分割数据库
| 数据库 | 使用的论文 | 创建的论文 | 规模 | 标注类型 | 建库过程 | 其它 |
|---|---|---|---|---|---|---|
| Matterport3D | Matterport3D: Learning from RGB-D Data in Indoor Environments 3DV |
90座建筑,总共包含194,400张RGB-D图像,10,800个全景图和24,727,520个带纹理的三角形;我们提供了使用[21]和[25]获得的带纹理网格重建 | 彩色和深度图像、相机姿态、带纹理的3D网格、建筑平面图和区域注释、实例级别语义注释(室内场景) | 1. 使用一个装在三脚架上的摄像机装置,配备三个彩色和三个深度相机,它们轻微向上、水平和轻微向下指向。对于每个全景图,它围绕重力方向旋转到6个不同的方向,在每个方向上停下来,从每个3个RGB相机获取一张HDR照片。3个深度相机在装置旋转时连续获取数据,这些数据被综合起来,与每张彩色图像合成一个对齐的1280x1024深度图像。每个全景图的结果是18张RGB-D图像,它们的投影中心几乎重合,大约在人类观察者的高度。对于数据集中的每个环境,操作员在整个可行走平面图上均匀间隔地捕获一组全景图,大约每隔2.5米。 2. 用户使用iPad应用程序标记窗户和镜子,并将数据上传到Matterport。然后,Matterport通过以下步骤处理原始数据:1)将每个全景图中的图像拼接成一个适合全景查看的“skybox”,2)使用全局束调整估计每张图像的6自由度姿态,3)重建一个包含环境中所有可见表面的单一带纹理网格。 |
niessner/Matterport: Matterport3D is a pretty awesome dataset for RGB-D machine learning tasks :) (github.com) | |
| Structured3D | Structured3D: A Large Photo-realistic Dataset for Structured 3D Modeling ECCV |
3.5k房屋涉设计,21,835个房间的真实3D结构注释,以及这些房间的超过196k幅2D渲染图像 | 平面、框线、立方体、房屋布局、房屋平面图、抽象3D结构 (室内场景) |
Structured3D Dataset (structured3d-dataset.org) 可以利用该数据集渲染出全景图(含有semantic 分割) |
||
| Stanford 2D3DS | Orientation-Aware Semantic Segmentation on Icosahedron Spheres ICCV 2019 |
Joint 2d-3d-semantic data for indoor scene understanding arxiv 2017 |
1413张等距柱状投影的 RGB-D 图 类别: 13 |
3D Mesh, semantics in 2D/3D, depth, surface normals (室内场景) |
alexsax/2D-3D-Semantics: The data skeleton from Joint 2D-3D-Semantic Data for Indoor Scene Understanding (github.com) | |
| PASS | PASS: Panoramic annular semantic segmentation ITS 2019 |
共1050张,其中400张有标注 | semantic(街道场景) 类别: 4(扩展后+2) |
1. 视角360◦×75◦ (30◦-105◦);分辨率2048×692 2. 在 4 个关键街道场景类别上进行了精细的标注:汽车、道路、人行横道和路缘 3. 后续扩展工作添加了Sidewalk 和 Person类别 4. 由中国杭州的一种可穿戴全景环状相机捕获的 |
elnino9ykl/PASS: Panoramic Annular Semantic Segmentation (github.com) | |
| SYNTHIA-PANO | Semantic segmentation of panoramic images using a synthetic dataset AILMDA 2019 |
Semantic segmentation of panoramic images using a synthetic dataset AILMDA 2019 |
Seqs02-fall: 461 Seqs02-summer: 556 Seqs04-fall: 738 Seqs04-summer: 694 Seqs05-summer: 787 类别: 13 |
semantic (街道场景,虚拟) |
1. 从虚拟图像数据集SYNTHIA构建(包含精细标注的传统FoV图像) 2. 设法将从不同方向拍摄的图像拼接成全景图像,并连同它们的标注图像 |
https://github.com/Francis515/SYNTHIA-PANO 1. SYNTHIA数据集是由计算机3D城市交通场景模型创建的,其中的所有图像都是虚拟图像。它包含一些称为SYNTHIA-Seqs的子集,其中的图像是由虚拟城市中移动汽车上的四个面向左、前、右和后方向的摄像机拍摄的。此外,还有不同城市场景、季节、天气条件等的图像。标签包含16个类别。我们所做的是将这四个方向的图像拼接成全景图像。 2. 由于是拼接的,存在盲区! |
| Omni-SYNTHIA | Orientation-Aware Semantic Segmentation on Icosahedron Spheres ICCV 2019 |
Orientation-Aware Semantic Segmentation on Icosahedron Spheres ICCV 2019 |
选择了所有五个地点的“夏季”序列 训练集: 1818 验证集: 451 类别: 13 |
semantic (街道场景,虚拟) |
1. 从虚拟图像数据集SYNTHIA构建(包含精细标注的传统FoV图像) 2. 使用插值对RGB数据;最近邻法对标签进行二十面体网格填充 |
1. SYNTHIA数据集是由计算机3D城市交通场景模型创建的,其中的所有图像都是虚拟图像。它包含一些称为SYNTHIA-Seqs的子集,其中的图像是由虚拟城市中移动汽车上的四个面向左、前、右和后方向的摄像机拍摄的。此外,还有不同城市场景、季节、天气条件等的图像。标签包含16个类别。我们所做的是将这四个方向的图像拼接成全景图像。 2. 由于是拼接的,存在盲区! |
| OmniScape | The OmniScape dataset ICRA 2020 |
见网站 | 1. 论文中:从摩托车前两侧获取的立体鱼眼/立体猫眼图像, depth, semantic, 相机参数, 摩托车运动参数 2. Github上:Optical Flow, Instance, 3D bounding boxes (机动两轮车上捕获的街道数据集,虚拟) |
从 CARLA,GTA V 中捕获 方法细节:《Génération d’images omnidirectionnelles à partir d’un environnement virtuel》 |
https://github.com/ARSekkat/OmniScape 全景图中间始终有一辆摩托车! |
|
| WildPASS | Is context-aware CNN ready for the surroundings? Panoramic semantic segmentation in the wild TIP 2021 Capturing omni-range context for omnidirectional segmentation CVPR 2021 |
Is context-aware CNN ready for the surroundings? Panoramic semantic segmentation in the wild TIP 2021 |
500张全景图 类别: 6(来自全球25个城市) |
semantic(街道场景) | 1. 尺寸2048×400,视场70°×360° 2. 类别:汽车、道路、人行道、人行横道、路缘和行人 3. 使用Google Street View;为每个城市提取20个全景图 |
https://github.com/elnino9ykl/WildPASS |
| DENSEPASS | DensePASS: Dense panoramic semantic segmentation via unsupervised domain adaptation with attention-augmented context exchange ITSC 2021 |
DensePASS: Dense panoramic semantic segmentation via unsupervised domain adaptation with attention-augmented context exchange ITSC 2021 |
训练/未标记: 2000 测试/标记: 100 类别: 19 |
semantic(街道场景) | Page not found · GitHub 1. 专门为PINHOLE→PANORAMIC转移而构建 2. 尺寸2048×400 3. 使用Google Street View收集的,涵盖了来自不同大陆的图像(测试用25个不同城市,训练用40个) |
|
| WildPPS | Panoramic Panoptic Segmentation - Towards Complete Surrounding Understanding via Unsupervised Contrastive Learning IVS 2021 |
Panoramic Panoptic Segmentation - Towards Complete Surrounding Understanding via Unsupervised Contrastive Learning IVS 2021 |
40张全景图(来自全球40个城市) 类别: 4 |
panoptic (街道场景) |
1. 尺寸为400 × 2048,视场为70°×360° 2. 标注了对街道场景理解最相关的类别,包括 stuff 类别街道和人行道以及 thing 类别人和车 |
https://github.com/alexanderjaus/PPS 对于有监督训练,我们依赖于已经存在的大量标注的针孔图像数据集,如Cityscapes和Mapillary Vistas |
| WOD:PVPS | Waymo Open Dataset: Panoramic Video Panoptic Segmentation ECCV 2022 |
Waymo Open Dataset: Panoramic Video Panoptic Segmentation ECCV 2022 |
100k相机照片 2,860条视频序列 类别:28 从6个城市,在各种时间、天气状况下采集 由两个数据集组成: 1. 感知数据集,包含高分辨率传感器数据和2030个分割的标签; 2. 运动数据集,包含对象轨迹和对应的103354个标签的3D地图 |
panoptic video (街道场景) |
WOD介绍: 包含1,150个场景,每个场景包含20秒的数据,以10 Hz的频率捕获 每个数据帧包括来自激光雷达设备的3D点云、来自五个摄像头(位于前、前左、前右、侧左和侧右)的图像,以及人类在激光雷达点云和摄像头图像中分别标注的3D和2D边界框的真实标签。每个边界框都包含一个在整个场景中对该对象唯一的ID。对于激光雷达数据,这允许在整个场景中进行跟踪。对于摄像头数据,这些ID仅在每个摄像头的图像内保持一致 基于Waymo Open Dataset (WOD)构建,由5个摄像头组成全景视频(220°),唯一一个在多个摄像头和时间上都一致的泛视觉分割注释的数据集。 拼接方法: 首先使用WOD提供的五个摄像头的外参和内参,将每个像素坐标反投影到3D空间。然后,我们设置一个位于所有五个摄像头中心的几何平均位置的虚拟摄像头[63],并使用双线性采样从3D空间通过等矩形投影计算像素颜色。对于对应于多个摄像头视图的像素,我们根据每个像素在全景图中到每个摄像头视图边界的距离计算权重。对于泛视觉标签,我们使用五个摄像头和虚拟摄像头的相机参数,通过最近采样计算每个摄像头视图中的标签。然后我们使用Qiao等人[54]的方法来拼接全景图标签,以保持视图一致性。 |
About – Waymo Open Dataset 官网上有非常详细的介绍 |
| CVRG-Pano | Semantic segmentation of outdoor panoramic images SIVP 2022 |
Semantic segmentation of outdoor panoramic images SIVP 2022 |
600张 (训练446, 验证48, 测试76) 类别: 20(属于7个组) |
semantic(街道场景) | 1. 属于匹兹堡的城市和郊区地区,从Google Street View下载,人工标注耗时约 500 man-hour 2. 训练中,还使用一种快速生成全景图像语义掩模的方法:首先,我们生成全景图像的立方体贴图。然后,每个立方体贴图的语义掩模是通过一个最先进的分割CNN模型生成的(我们使用了在Cityscapes上训练的HRNet-OCR[29])。最后一步,我们将所有立方体贴图的语义掩模投影到全景图上。 |
semihorhan/semseg-outdoor-pano: Semantic segmentation of outdoor panoramic images using UNet-stdconv and UNet-equiconv. CVRG-Pano: semantically annotated outdoor panoramic image dataset. (github.com) |
| SynPASS | Behind every domain there is a shift: Adapting distortion-aware vision transformers for panoramic semantic segmentation TPAMI 2024 |
Behind every domain there is a shift: Adapting distortion-aware vision transformers for panoramic semantic segmentation TPAMI 2024 |
9080张(cloudy, windy, foggy, sunny各2270张) 类别: 22 |
semantic(街道场景) | 1. 尺寸1,024×2,048 2. 类别:Building Fence Other Pedestrian Pole RoadLine Road SideWalk Vegetation Vehicles Wall TrafficSign Sky Ground Bridge RailTrack GroundRai TrafficLight Static Dynamic Water Terrain 3. 使用CARLA模拟器创建,虚拟传感器套件由6个位于同一视点的针孔相机组成,以获得立方体全景图像,使用立方体贴图到等矩形投影算法将获得的立方体贴图全景重新投影到通用的等矩形格式中 4. 利用8个开源城市地图,并在每个地图中设置了100到120个初始收集点。我们的虚拟收集车辆按照模拟器的交通规则行驶。我们每50帧采样一次,并在每个初始收集点保留前10个关键帧图像。为了确保收集数据的多样性,我们调节了天气和时间条件 |
SOD 数据库
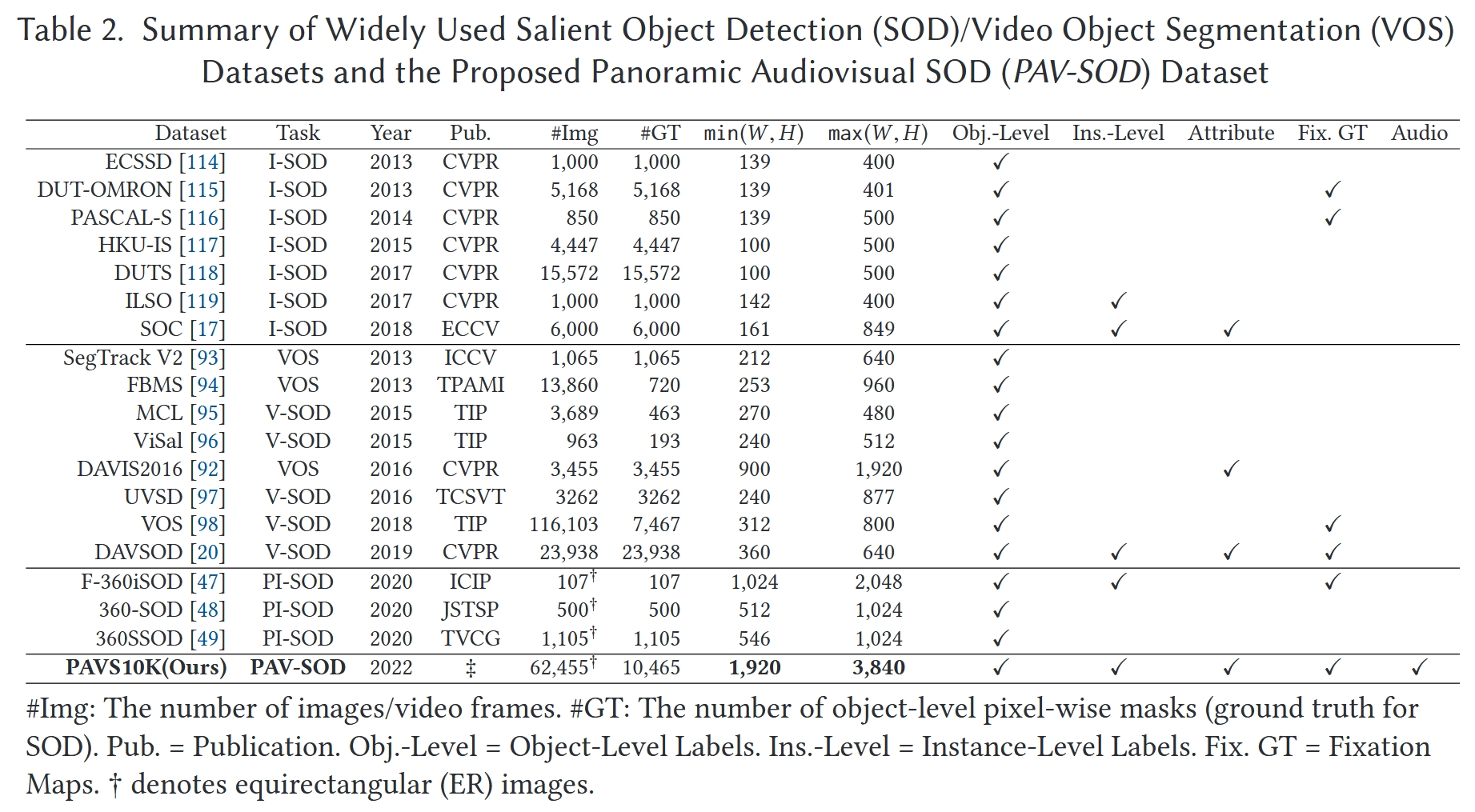
截至 2023 年
| 数据库 | 使用的论文 | 创建的论文 | 规模 | 标注类型 | 建库过程 | 其它 |
|---|---|---|---|---|---|---|
| 360SOD | Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information ETCI 2023 |
Distortion-adaptive salient object detection in 360° omnidirectional images TVCG 2020 |
500张(400张训练图像、100张测试图像) 分辨率512 × 1024 |
object-level、human fixation | 第一个全景 SOD 数据集 | |
| F-360iSOD | A FIXATION-BASED 360◦ BENCHMARK DATASET FOR SALIENT OBJECT DETECTION ICIP 2020 |
107张 1165个显著物体 分辨率512 × 1024 |
object+instance level | Jun-Pu/F-360iSOD: A dataset for fixation-based salient object segmentation in 360° images (github.com) | ||
| 360SSOD | Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information ETCI 2023 |
Stage-wise salient object detection in 360° omnidirectional image via object-level semantical saliency ranking TVCG 2020 |
1105张(850张训练图像、255张测试图像) 分辨率546 × 1024 |
object level | 360-SSOD/download (github.com) | |
| ASOD60K (全景视频) PAVS10K的前身 |
ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos Arxiv 2021 |
ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos Arxiv 2021 |
来自67个全景视频的62,455视频帧,其中10,465个关键帧被赋予了标签 分辨率4K |
head movement (HM) and eye fixations, bounding boxes, object-level masks, and instance-level labels | https://github.com/PanoAsh/ASOD60K 视频具有超类和子类 花费一年建立数据集 |
|
| ODI-SOD | View-Aware Salient Object Detection for 360∘ Omnidirectional Image TM 2022 |
View-Aware Salient Object Detection for 360∘ Omnidirectional Image TM 2022 |
6263张分辨率不低于2K的RP图像 (从Flickr网站收集的1,151张图片和从YouTube精选的5,112帧视频) 2,000张图片的测试集 4,263张图片的训练集 分辨率不低于2K |
object level | 1. 使用不同的对象类别关键词(例如,人类、狗、建筑)在Flickr和YouTube上搜索全景资源,参考MS-COCO类别以涵盖各种真实世界场景。收集了8,896张图片和998个视频,包括不同的场景(例如,室内、室外)、不同的场合(例如,旅行、体育)、不同的运动模式(例如,移动、静态)和不同的视角。然后,所有视频都被采样成关键帧,并将不令人满意的图片或帧(例如,没有显著对象、质量低)剔除。 3. 首先,我们要求五位研究人员通过投票来判断对象的显著性,并选择显著的对象。其次,注释方面手动根据选定的显著对象标记二进制遮罩。最后,五位研究人员交叉检查二进制遮罩,以确保准确的像素级对象级注释。 |
iCVTEAM/ODI-SOD: A 360° omnidirectional image-based salient object detection (SOD) dataset referred to as ODI-SOD with object-level pixel-wise annotation on equirectangular projection (ERP). (github.com) 所选图像的显着区域数量从一个到十个以上,显着区域的面积比从小于0.02%到大于65%,分辨率从2K到8K,一半以上的场景很复杂并且包含不同的对象 |
| PAVS10K (全景视频) |
PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection ACMMCC 2023 |
PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection ACMMCC 2023 |
训练视频:40个,共5796帧 测试视频:27个共4669帧 |
instance level、眼动数据 | 1. 通过使用多个搜索关键词(例如,360°/全景/全向视频,空间音频,环境声学)从YouTube获取,涵盖了各种真实世界动态场景(例如,室内/室外场景)、多种场合(例如,体育、旅行、音乐会、采访、戏剧)、不同的运动模式(例如,静态/移动摄像机)以及多样化的对象类别(例如,人类、乐器、动物) 2. 获得了67个高质量的4K视频序列,手动将视频剪辑成小片段(平均29.6秒),以避免在收集眼动注视点时产生疲劳,总共有62,455帧,记录了62,455 × 40个眼动注视点 3. 所有的视频片段都是通过内置有120 Hz采样率的Tobii眼动追踪器的HTC Vive头戴式显示器(HMD)来展示,并收集眼动注视点。观察者。我们招募了40名参与者(8名女性和32名男性),年龄在18到34岁之间,他们报告说视力正常或矫正到正常。20名参与者被随机选中观看单声道声音的视频(第一组),而其他参与者观看没有声音的视频(第二组) 4. 这67个子类别可以根据主要声源的线索被归类为三个超类别,即说话(例如,对话、独白)、音乐(例如,唱歌、演奏乐器)和杂项(例如,街道上汽车引擎和喇叭的声音、露天环境中的人群噪音) 5. 从总共62,455帧中以1/6的采样率统一提取了10,465帧,用于像素级注释,使用CVAT工具箱进行手动标记 6. 3位资深研究人员参与了基于注视的显著对象的10,465帧的手动注释,最终获得了19,904个实例级显著对象标签 |
https://github.com/ZHANG-Jun-Pu/PAV-SOD 第一个用于全景视频SOD的数据集 |
| 未发布 (全景视频,SOR) |
Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking ACMMM 2024 |
Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking ACMMM 2024 |
instance level | 根据多个观察者的注意力转移为PAVS10K数据集提供了真实的显著性排名 | 未公开 第一个用于全景视频SOR的数据集 |
